シリーズ: モデルベース要件定義手法RDRA
- 要件定義手法RDRAの概要と全体像
- RDRAによる要件定義の進め方〜第1フェーズ:枠組みを作る
- RDRAによる要件定義の進め方〜第2フェーズ:要件を組み立てる
- RDRAによる要件定義の進め方〜第3フェーズ(1):システムレイヤーの要素同士を関連付ける
- RDRAによる要件定義の進め方〜第3フェーズ(2):矛盾を解消し、整合性を高める
- RDRAの成果物と設計プロセスとの連携
- 要件定義をAIで加速する「RDRAAgent」その1〜LLMがモデルの叩き台を自動生成(本記事)
- 要件定義をAIで加速する「RDRAAgent」その2〜要件を仕様化するRDRASpec
- RDRAで見積りを行う方法その1〜要件モデルから工数・金額を自動算出する
- RDRAで見積りを行う方法その2〜ウォーターフォール開発・工数編
- RDRAで見積りを行う方法その3〜ウォーターフォール開発・工期、金額編
- RDRAで見積りを行う方法その4〜アジャイル開発編
TRACERYプロダクトマネージャーの haru です。
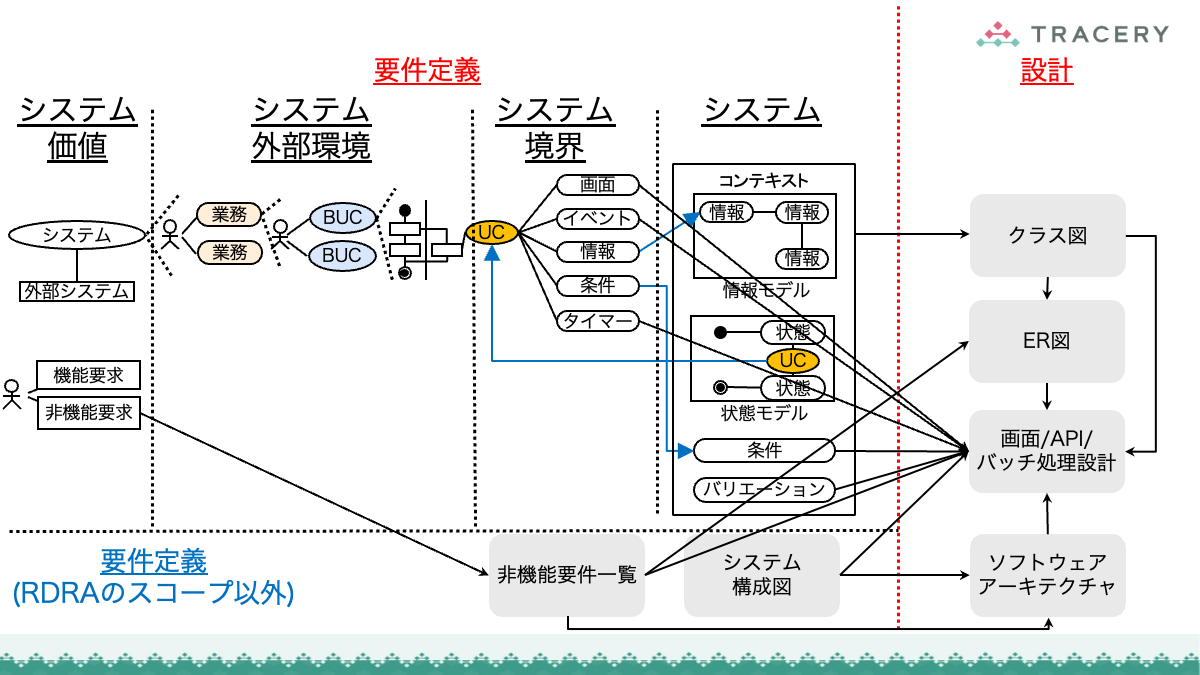
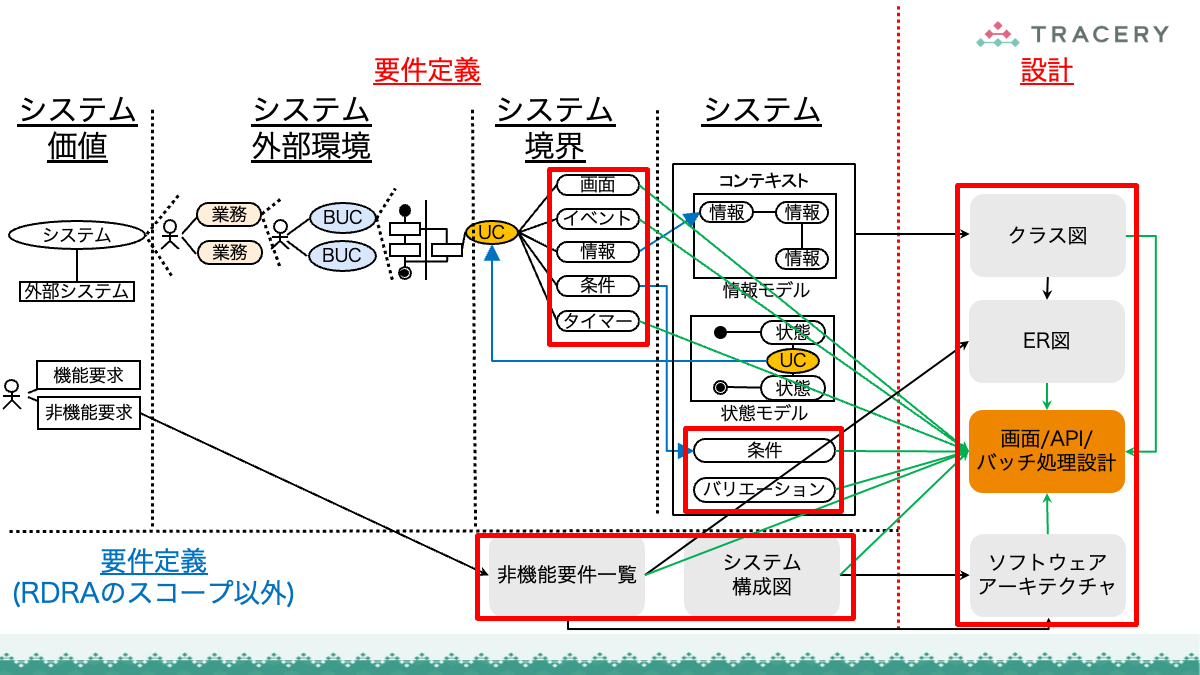
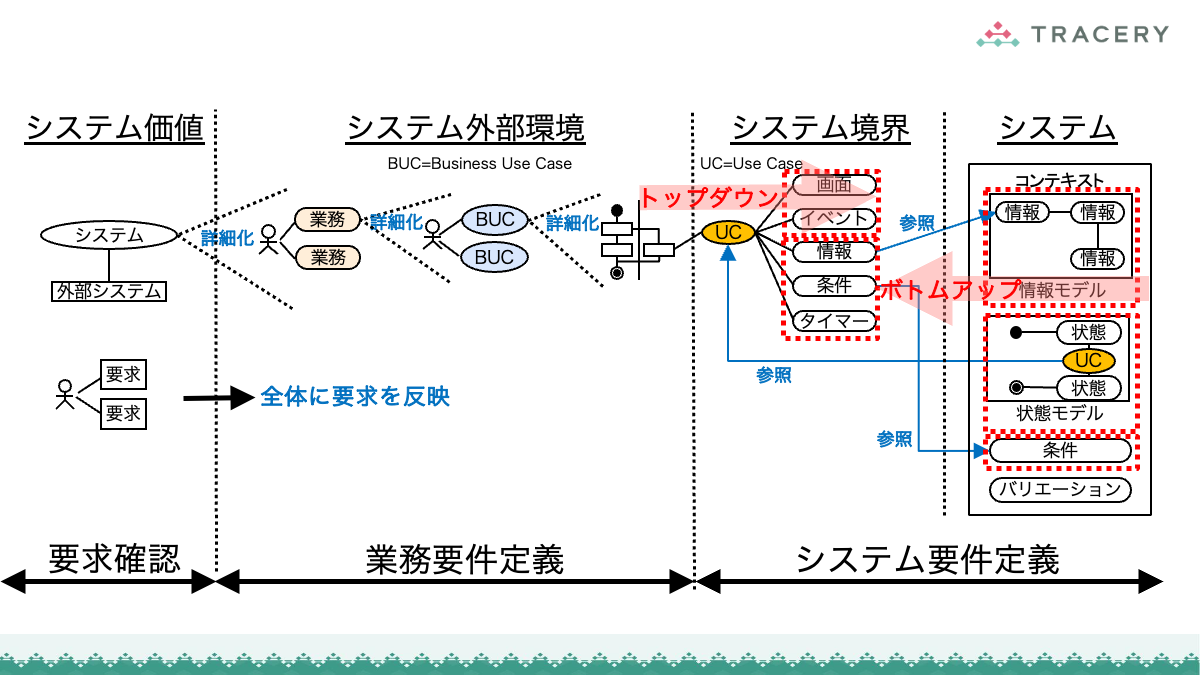
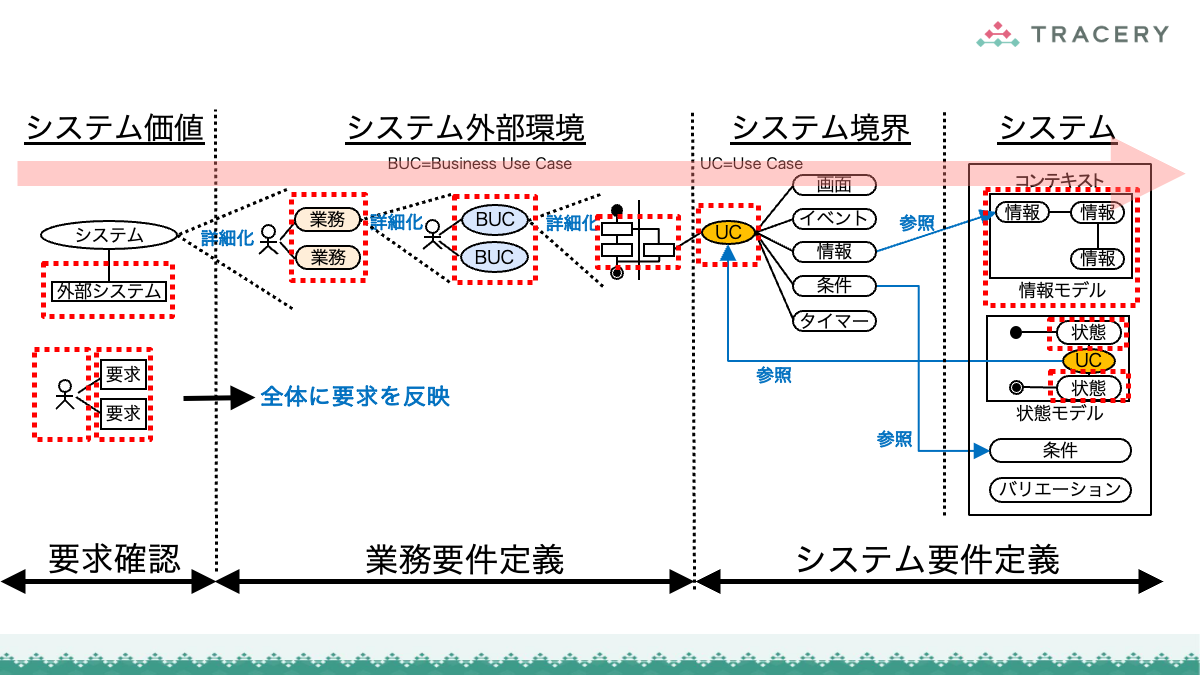
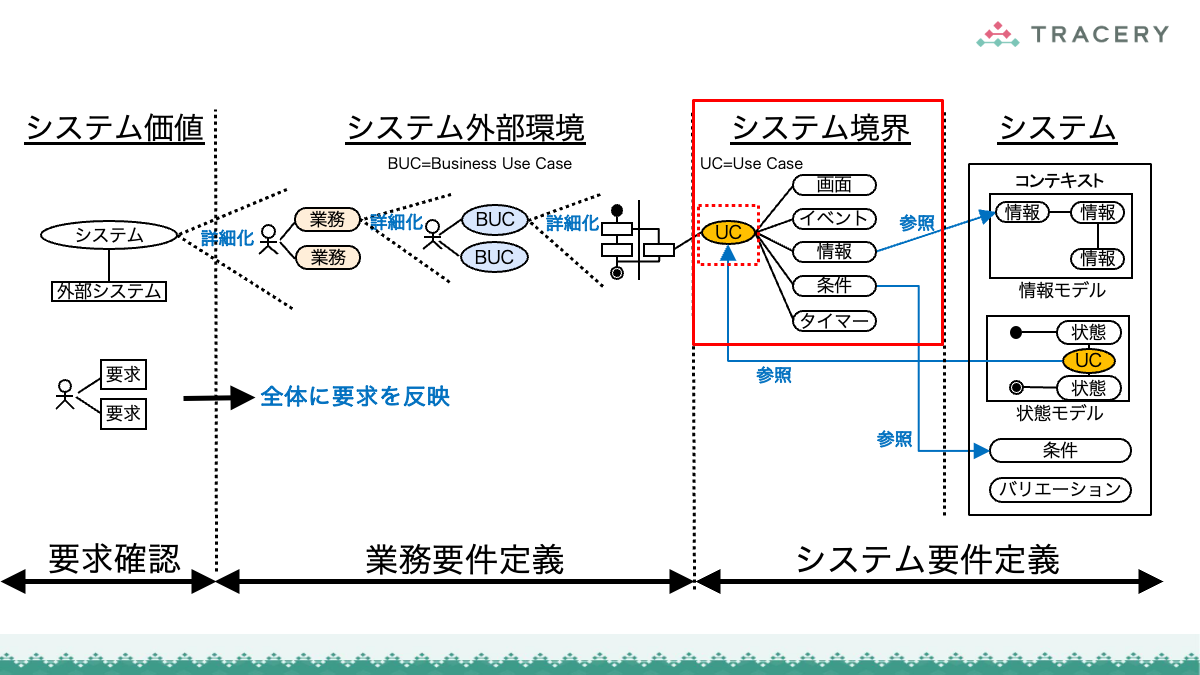
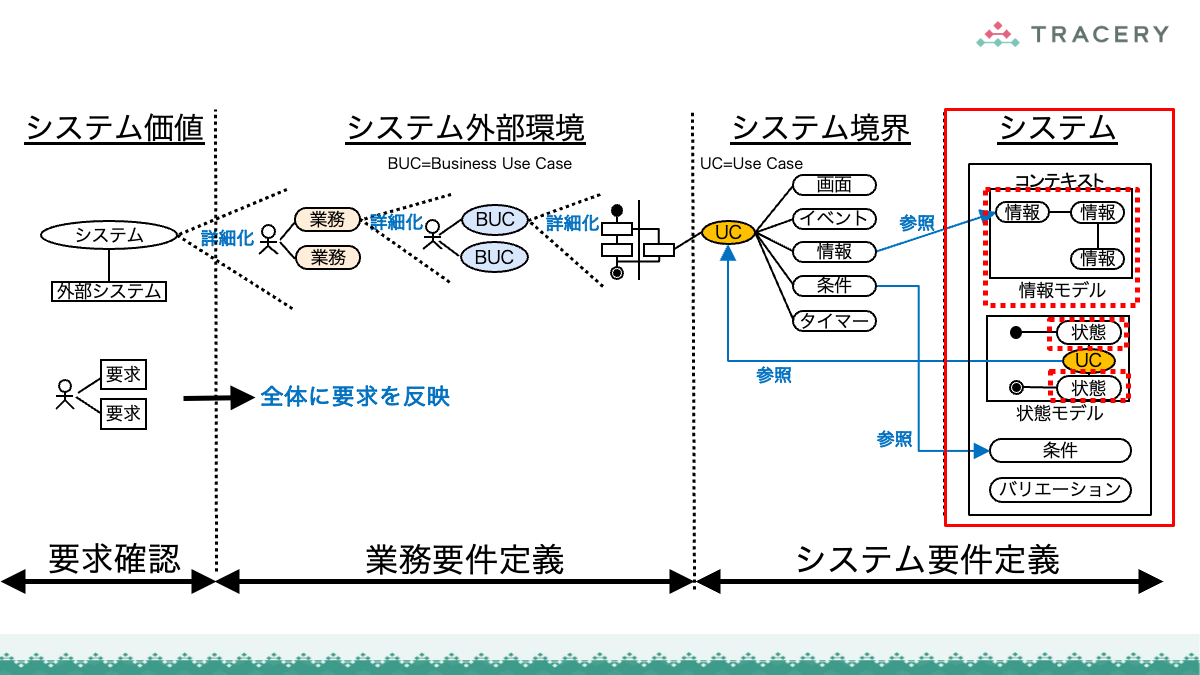
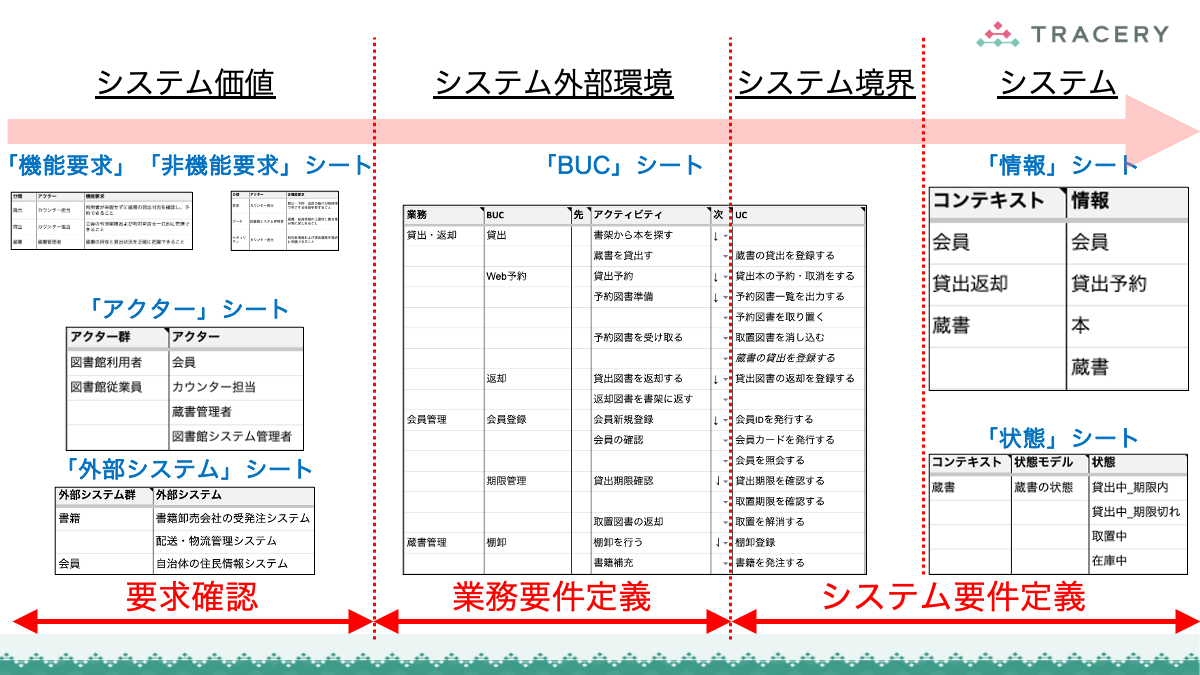
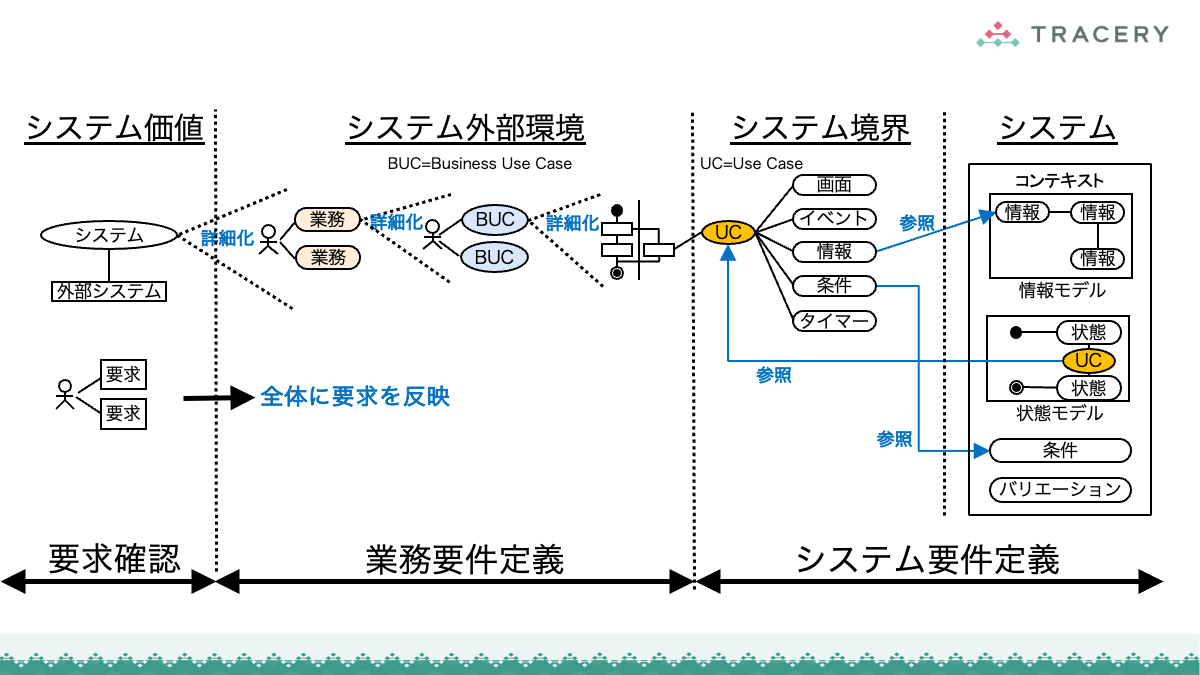
本連載ではこれまで、RDRAの第1フェーズから第3フェーズまでの手順を通じ、業務とシステムを一体として構造化していくプロセスを解説してきました。
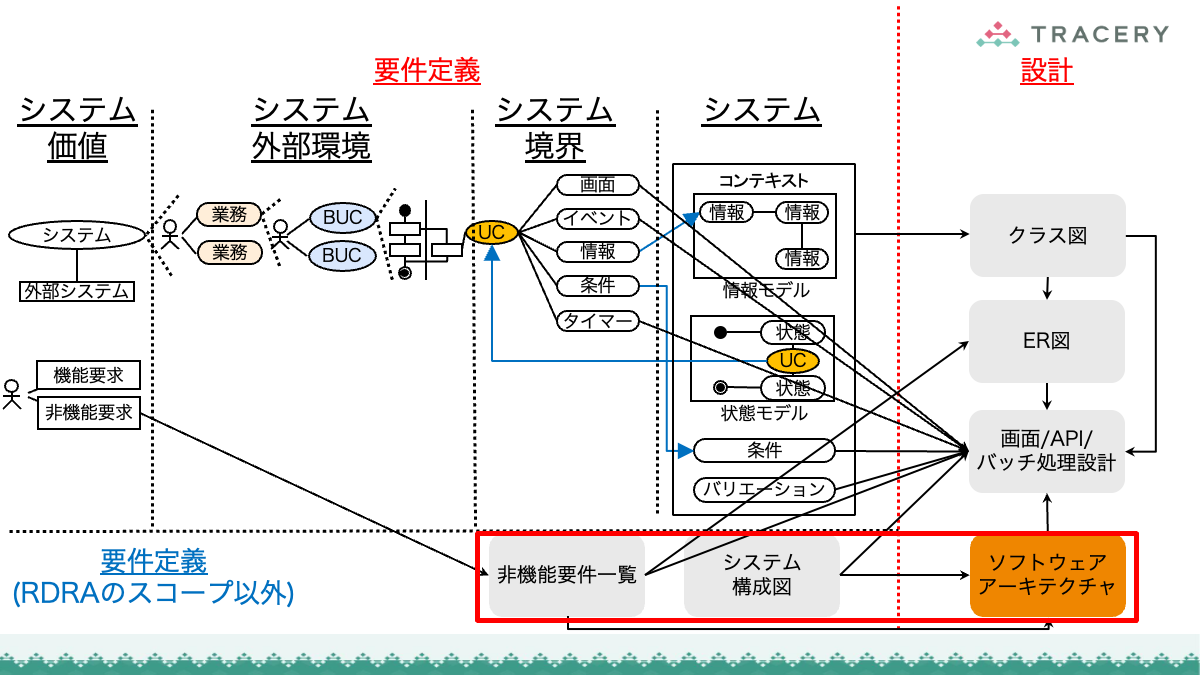
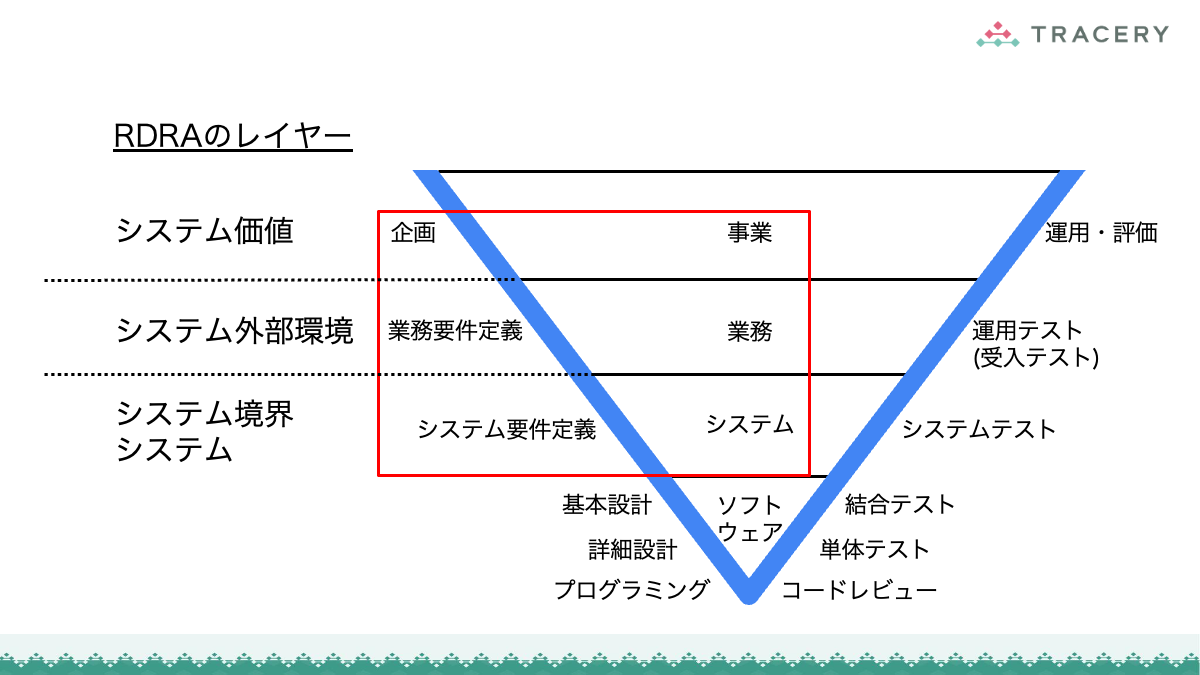
さらに前回は、定義したRDRAの成果物が、ソフトウェアアーキテクチャ設計やクラス設計などの設計プロセスにどのように引き継がれるかを整理しました。
RDRAによるアプローチは非常に強力ですが、どのような要件定義手法であっても共通する課題があります。
それは、要件定義立ち上げ時にかかる「全体像を描き出す労力」です。
ヒアリングやワークショップを重ねながら、関係する業務や機能の要素をひとつひとつ洗い出し、整理し、要件としてカタチにしていくという初期作業には、手法を問わず大きな労力がかかります。
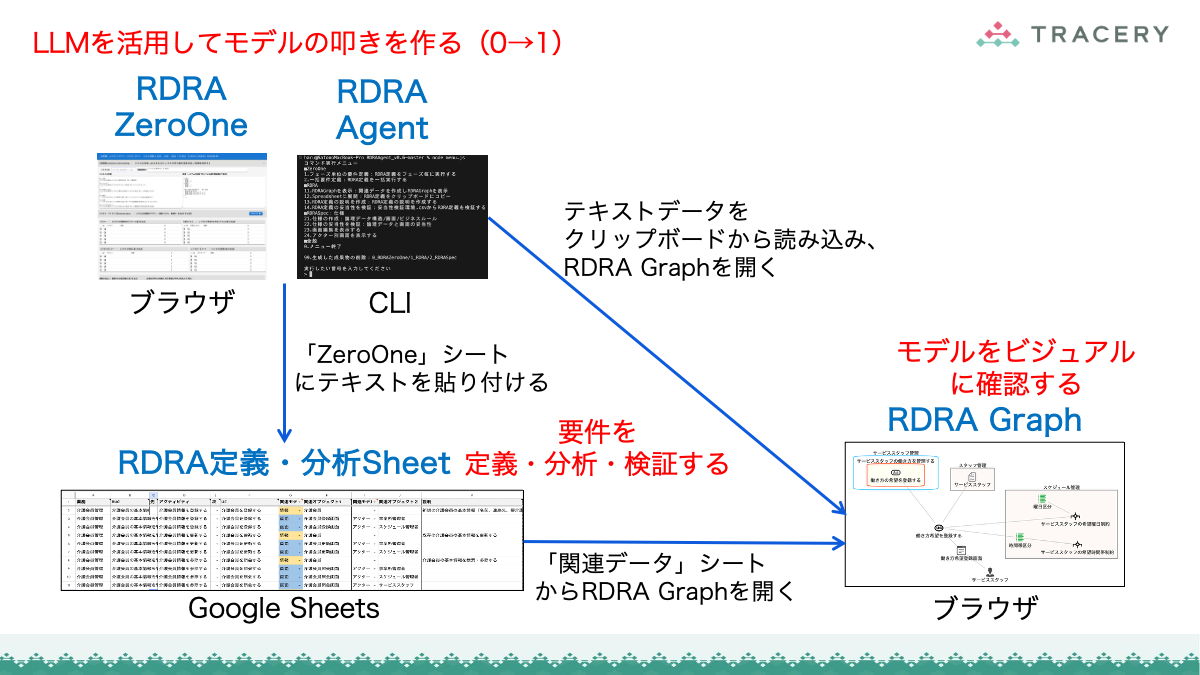
本記事では、要件定義立ち上げ時の初期作業の負担を大幅に軽減し、要件定義のスピードを劇的に加速させるAI Agentツール「RDRAAgent」を紹介します。
- RDRAAgentとは
- RDRAAgentのインストール方法
- RDRAAgentによる要件の生成
- RDRA定義・分析Sheetへのデータ連携
- RDRAAgentの活用がもたらす価値
- AIを活用した要件定義で人が担うべき責任
- 最後に
RDRAAgentとは
RDRAAgentは、LLM(大規模言語モデル)を活用し、要件の叩き台となるRDRA形式のモデルデータを自動生成する支援ツールです。
自然言語で記述された要望を読み込み、RDRAの構造に沿った要素(アクター、業務、ユースケース、情報など)を推論します。
RDRAAgentはCLI(コマンドラインインターフェース)から実行する形式で提供されており、GitHubで公開されています。
RDRAAgentのインストール方法
RDRAAgent の入手先(GitHub): https://github.com/kanzaki/RDRAAgent_v0.6
なお、本記事執筆時点のバージョンは0.6です。正式版のリリース時にはURLが変更される可能性があります。
RDRAAgentは外部依存関係がないため、ダウンロードまたはクローンするだけですぐに利用できます。
必要環境
- OS: Windows 11 / macOS
- Node.js: バージョン18以上推奨
- AIツール:Claude Code(デフォルト)または Cursor
方法1: GitHubから直接ダウンロード(推奨)
- GitHubリポジトリページの「Code」→「Download ZIP」を選択し、ZIPファイルをダウンロードして展開します。
方法2: リポジトリをクローン
- 開発やカスタマイズを行いたい場合は、以下のコマンドでクローンします。
git clone https://github.com/kanzaki/RDRAAgent_v0.6.git cd RDRAAgent_v0.6
npm install は不要です(外部依存関係がないため)。
- 起動方法 ターミナルで以下のコマンドを実行するとメニューが起動します。
node menu.js

RDRAAgentによる要件の生成
RDRAAgentによる要件の生成は、大きく以下の流れで進めます。
実行の流れ
初期要望.txtを編集するRDRAAgent_v0.6フォルダ直下にあるファイルを編集する
- 要件の生成
- RDRAAgentのメニューで、
1. フェーズ単位実行または2. 一括要件定義を選択する - LLMが
初期要望.txtの内容を解析・推論し、RDRAの構成要素として整理されたテキストデータを出力する
- RDRAAgentのメニューで、
「初期要望.txt」を編集する
「初期要望.txt」は、ユーザーが作成するRDRAAgentへの入力ファイルです。
デフォルトで以下のようなサンプルが保存されているので、要件定義対象のシステムに合わせて編集してください。
# 訪問介護システム ## 背景 介護業界では、介護会員の要望に合わせ、様々な法規の中でサービススタッフの多様な働き方でスケジュールを調整する必要がある ## 要求 ・サービススタッフの柔軟な働き方に対応しかつ介護会員の要望に合わせたスケジュール調整を行える仕組みを持つ ## ビジネスポリシー ・各サービススタッフの要望に合わせたスケジュール管理を行う ・訪問介護事業で小規模事業社を複数持つので、そこを一元管理を行う事業所をもつ ・サービススタッフの働き方は出来るだけ自由に設定できる ・サービススタッフのスキル別に出来る仕事を適切に配分する ・介護会員の要望に合わせたスケジュール調整を行う ・ビジネスパラメータの組合せに柔軟に対応できる業務形態にする ## ビジネスパラメータ ・介護会員とサービススタッフの自由度を保つために介護施設を分類できる ・サービススタッフの自由度を保つために働き方を細かく分類する ・介護会員の状況を細かく分類できる ## 業務概要 ・介護会員の管理(名前、連絡先などの様々な属性を管理) ・効率的な訪問介護の計画 ・訪問介護の実施記録を管理する ・介護費用の計算と請求及び回収
その他の「初期要望.txt」のサンプルは、Samplesフォルダに格納されていますので、参考にしてください。
要件の生成
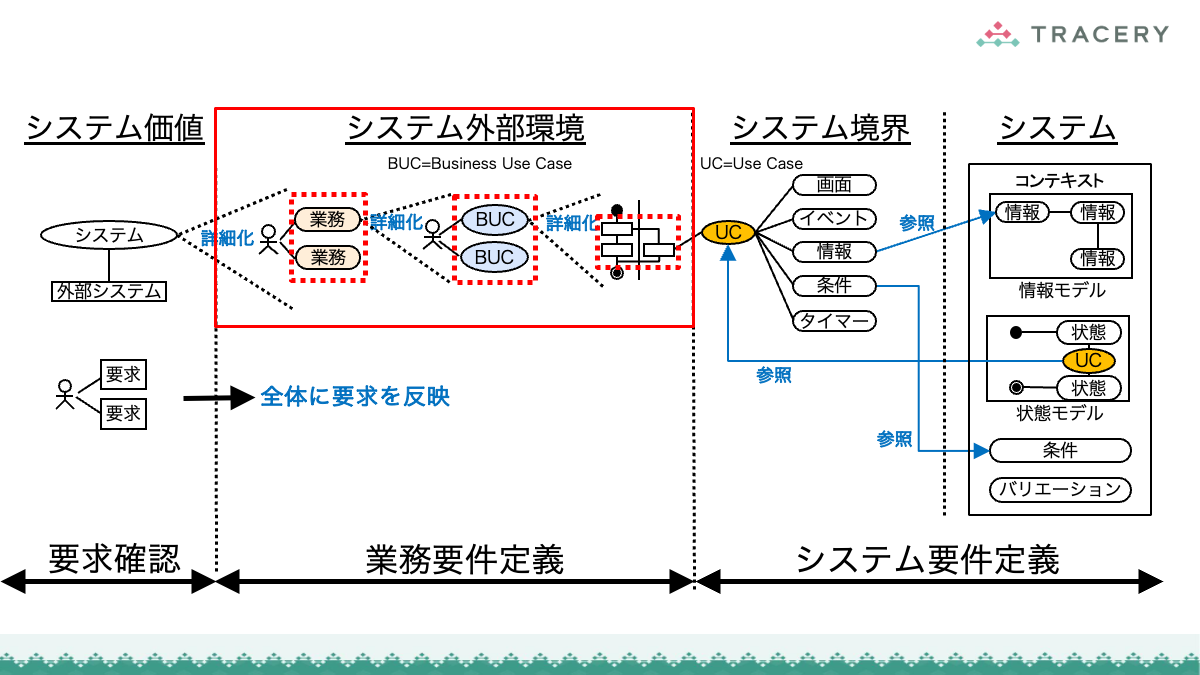
RDRAAgentの要件自動生成はフェーズ1〜4に分かれています*1。
RDRAAgentのメニューで、1. フェーズ単位実行 または 2. 一括要件定義 を選択します。
1. フェーズ単位実行:実行されていないフェーズを起点として1フェーズのみ実行する- 例:フェーズ2まで実行されていたらフェーズ3を実行する
- フェーズごとにファイル内容を確認・修正し、その後に次のフェーズに進みたい場合に使用する
2. 一括要件定義:実行されていないフェーズから最後のフェーズまでを一括で実行する- 例:フェーズ2まで実行されていたらフェーズ3、4を実行する
- すべてのファイルを一括で作成したい場合に使用する
生成ファイル
RDRAAgentでは、フェーズ1〜4の実行中に、まず0_RDRAZeroOneフォルダ配下に中間成果物のファイルが順次作成されます。フェーズ4まで完了すると、1_RDRAフォルダ配下に最終成果物のファイル群が生成されます。
中間成果物
中間成果物のファイルは、0_RDRAZeroOne フォルダの配下にフェーズごとのサブフォルダ(例: フェーズ1の場合は phase1)が作成され、各フェーズに対応するフォルダへ出力されます。
フェーズ1では以下のファイル群が出力されます。
- アクター.tsv
- バリエーション.tsv
- ビジネスパラメータ.tsv
- ビジネスポリシー.tsv
- 初期要望分析.md
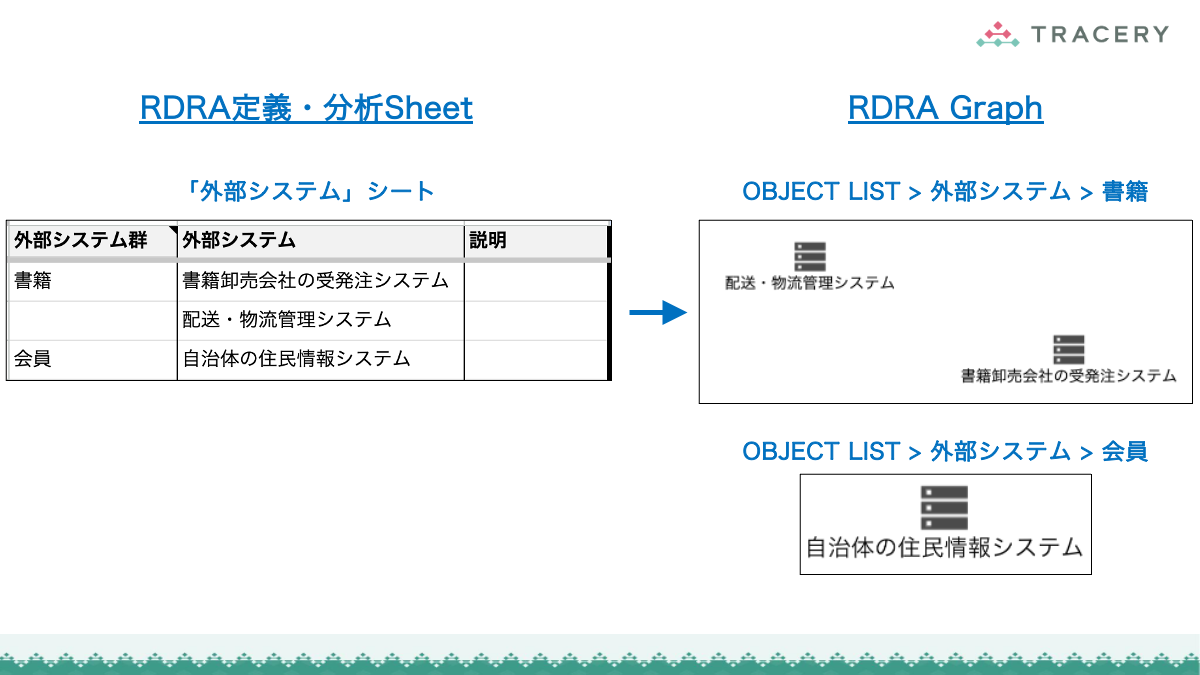
- 外部システム.tsv
- 情報.tsv
- 条件.tsv
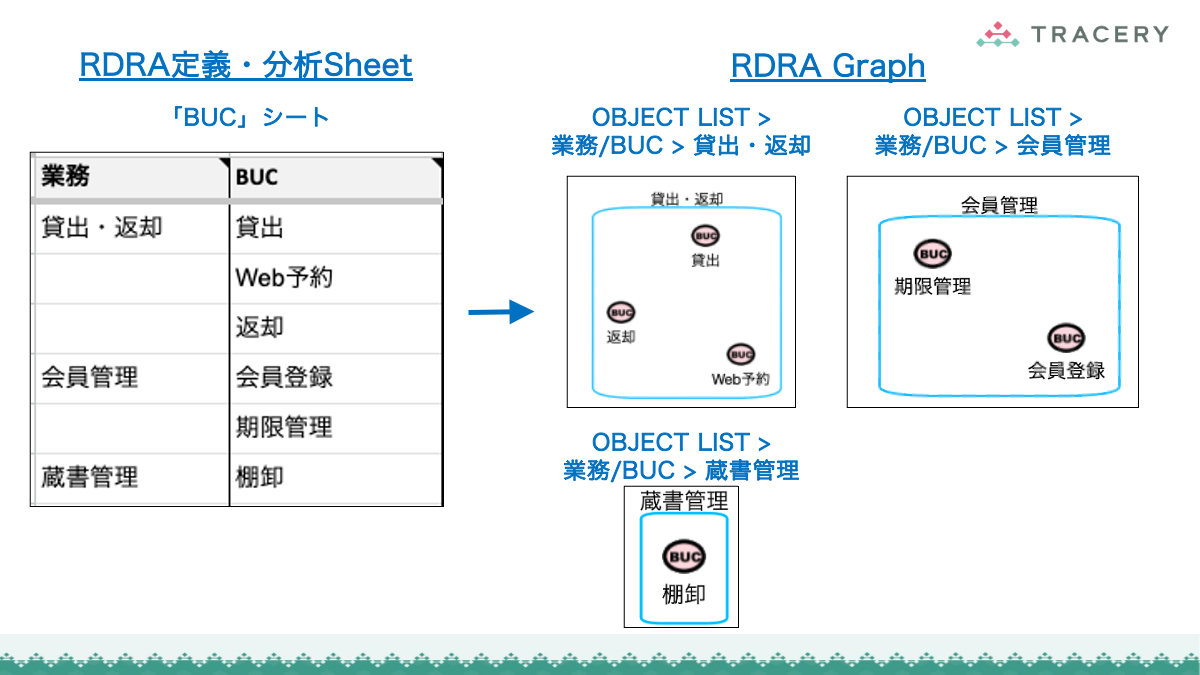
- 業務.tsv
- 状態.tsv
- 要求.tsv
メニューで 1. フェーズ単位実行 を選択した場合、これらのファイルの内容を確認・修正することで精度を上げてから次のフェーズに進むことができます。
最終成果物
全4フェーズの実行が完了すると、1_RDRA フォルダの配下に以下のファイル群が生成されます。
- システム概要.json
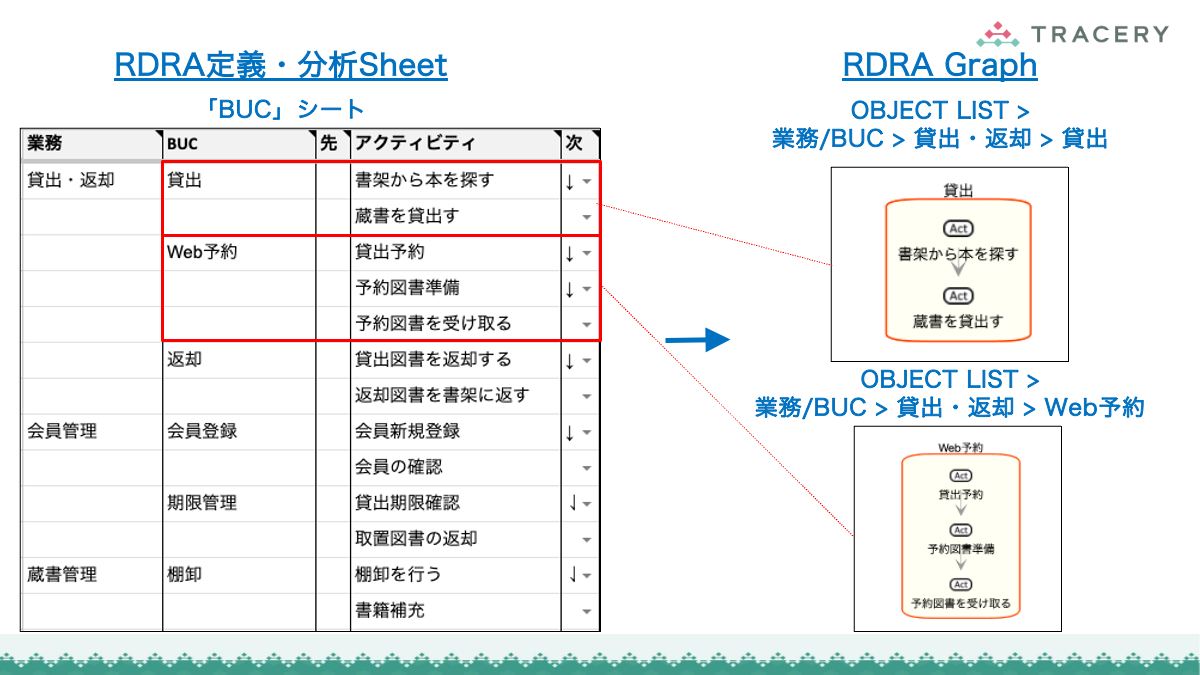
- BUC.tsv
- アクター.tsv
- バリエーション.tsv
- 外部システム.tsv
- 情報.tsv
- 条件.tsv
- 状態.tsv
- 関連データ.txt
- ZeroOne.txt
これらのファイルが出力されたら、以下のいずれかのメニューを選択して、生成結果を確認します(本記事では「12. Spreadsheetに展開」の手順で進めます)。
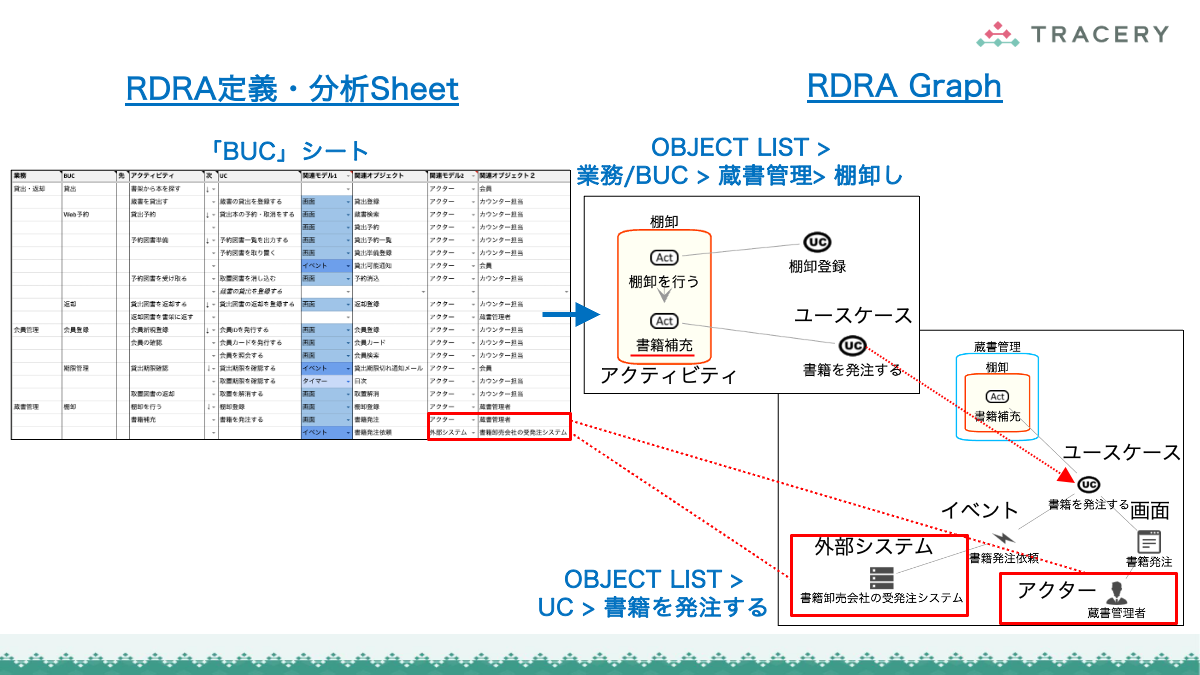
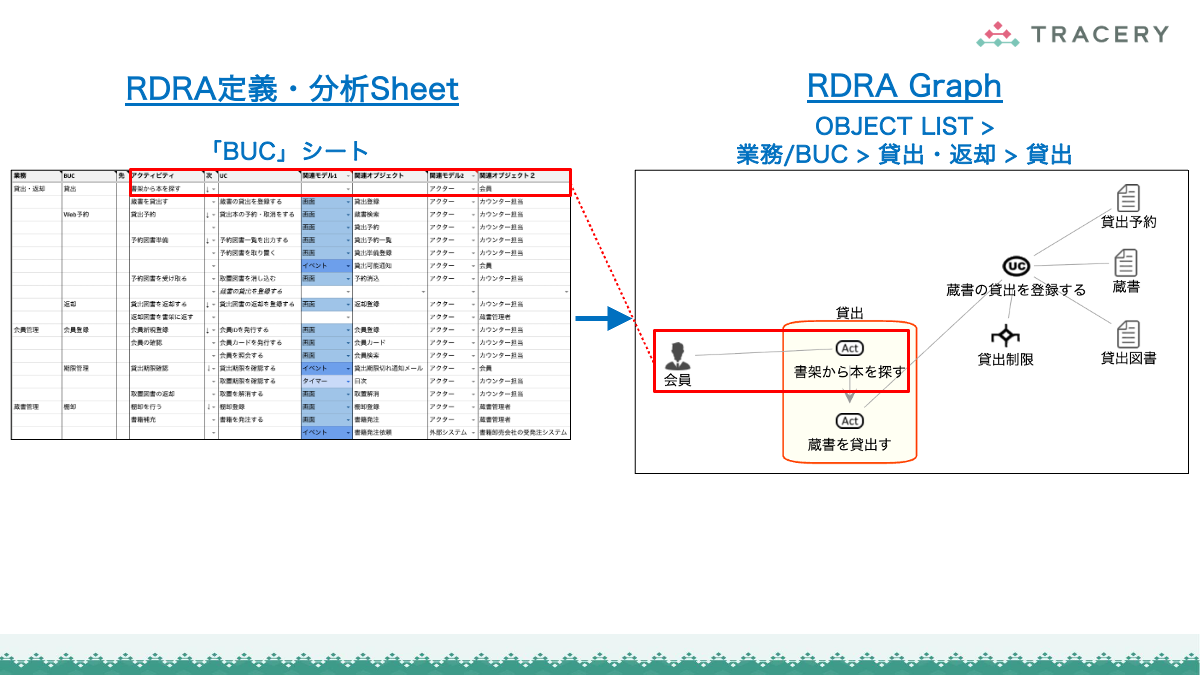
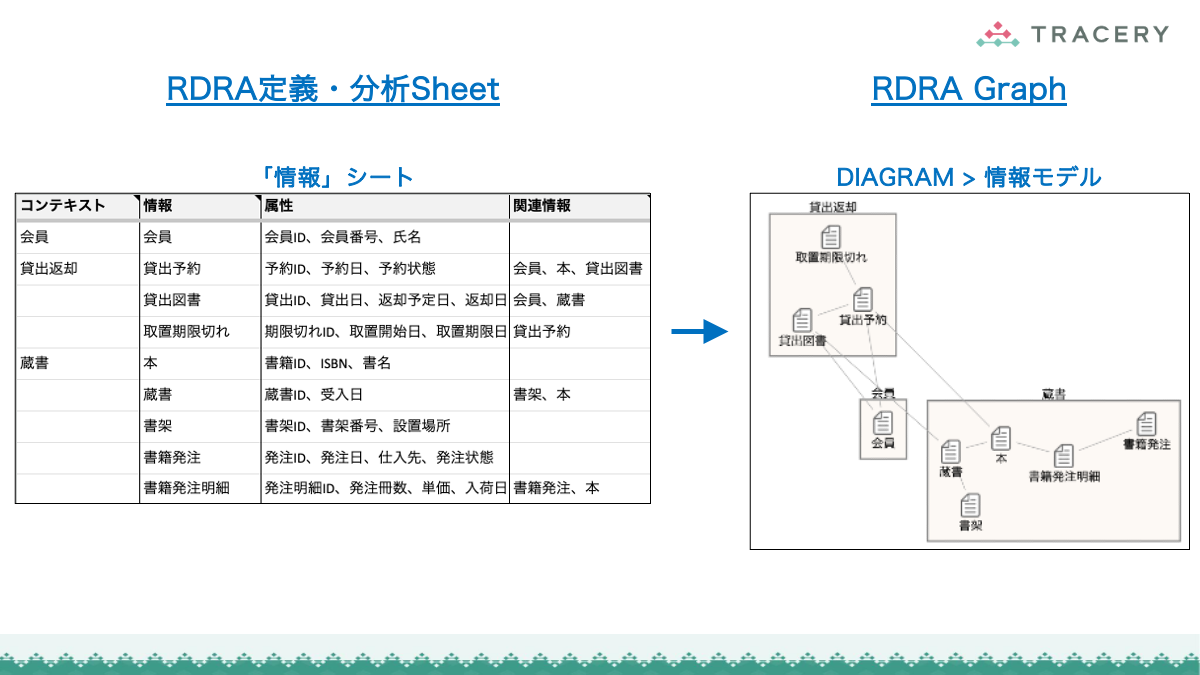
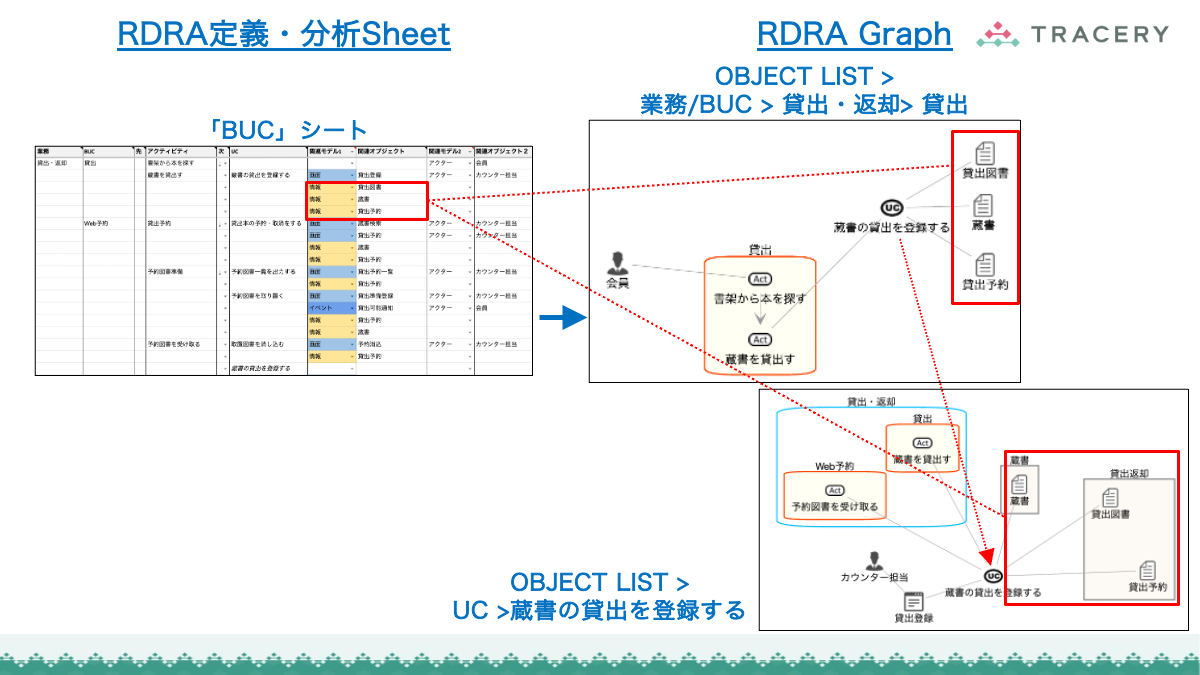
11.RDRAGraphを表示:関連データを作成しRDRAGraphを表示12.Spreadsheetに展開:RDRA定義をクリップボードにコピー
フェーズ単位の実行か一括要件定義か
RDRAAgentの開発者である神崎善司氏によると、LLMの性能が向上してきたことで、人が途中で介在せず一括で実行しても精度の高い結果が得られるようになってきているとのことです。
Modeling Forum 2025(2025年11月26日開催)での神崎善司氏の発表「要件定義の中心にモデルを置きLLMが出力した要件に責任をもつ」では、以下のように述べられていました。
- RDRAAgentのプロセスは複数のフェーズで構成されているが、各フェーズで人が要件を検証するのは負荷が大きい。
- そこで、フェーズ1のみ人が内容を確認し、その後は最終フェーズまで一気にAgentに生成させ、RDRA Graphでビジュアルに検証するほうが合理的である。
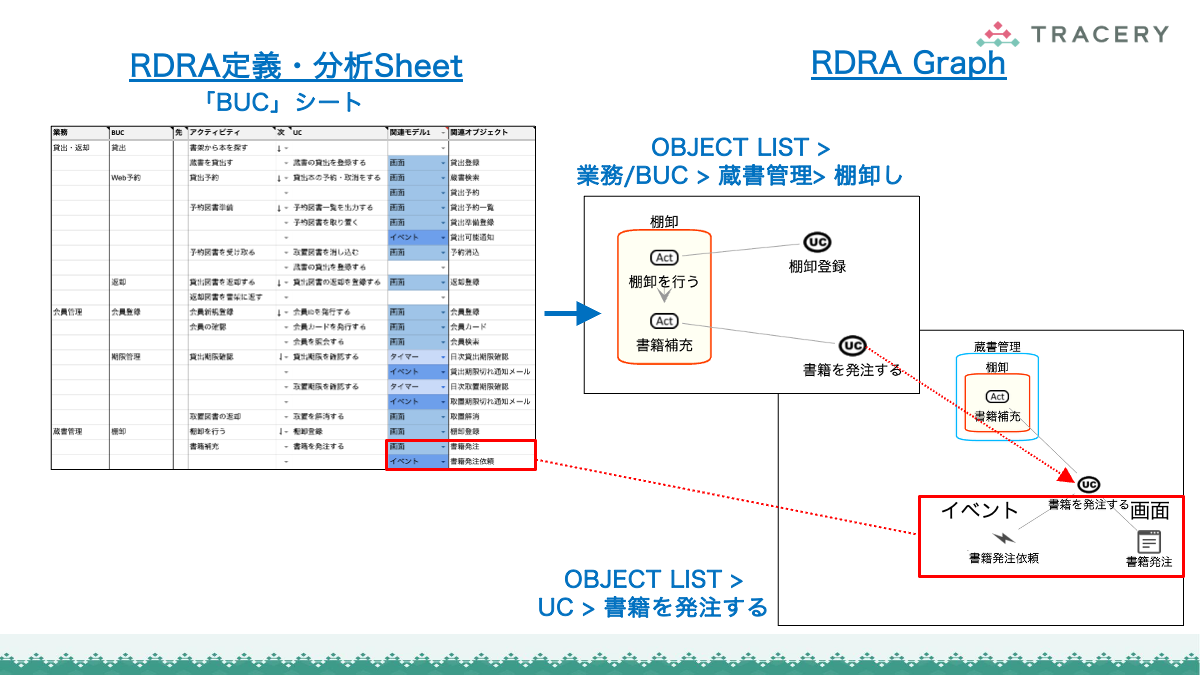
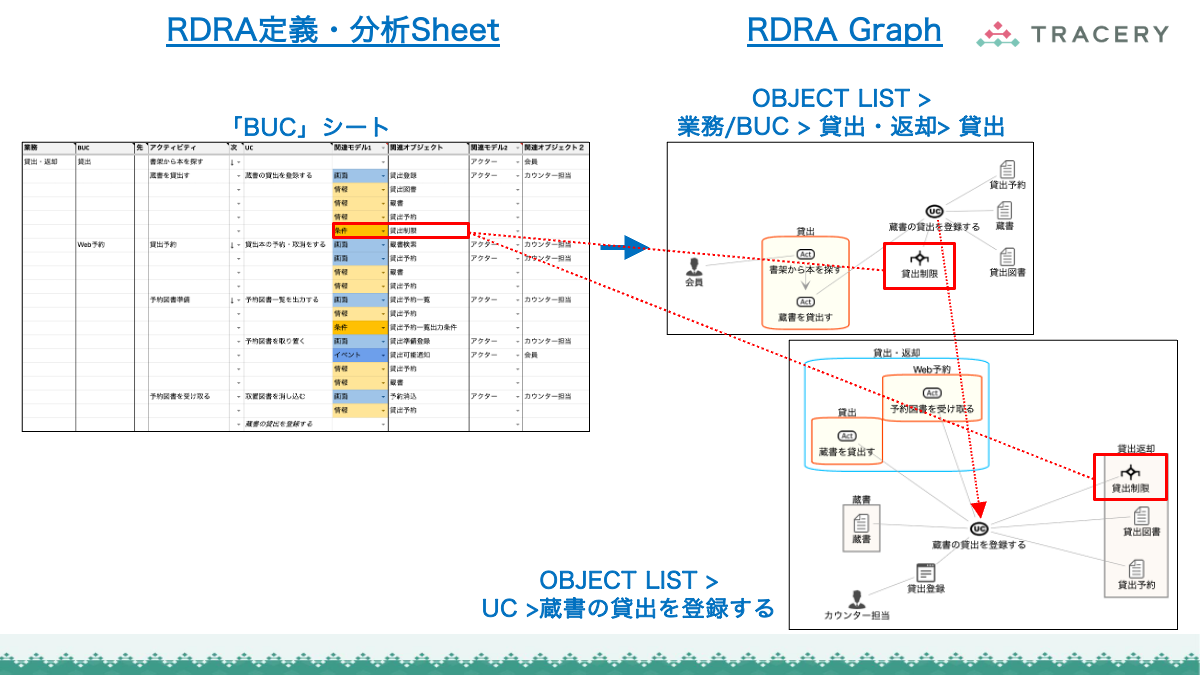
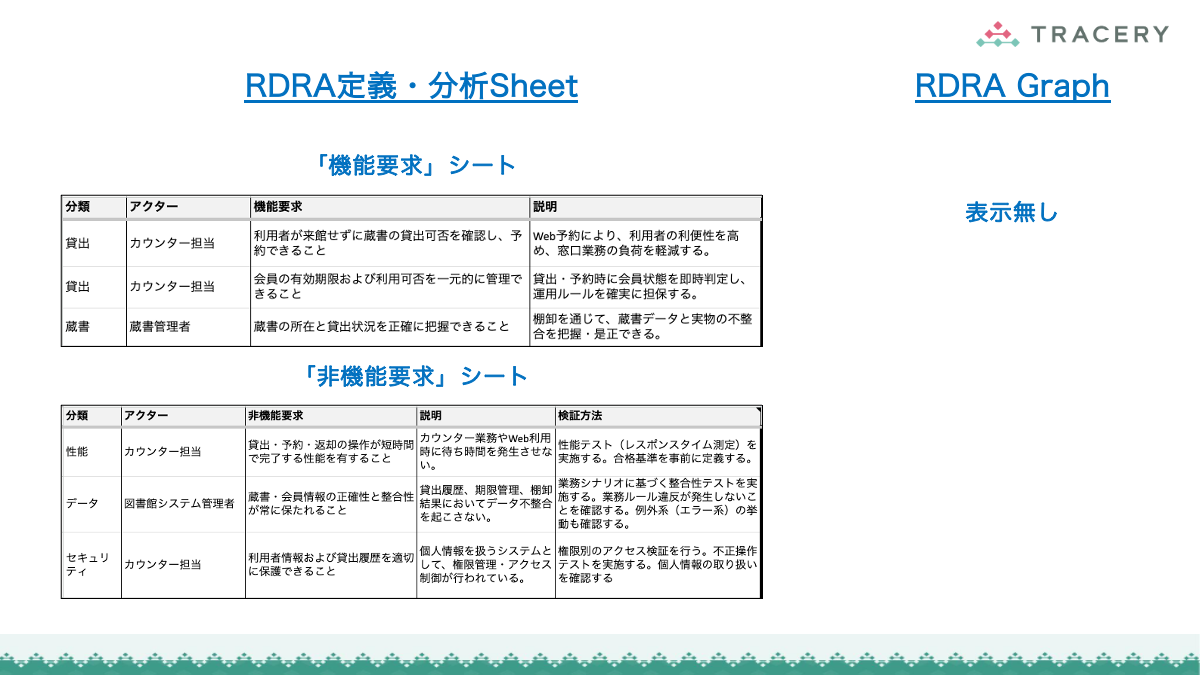
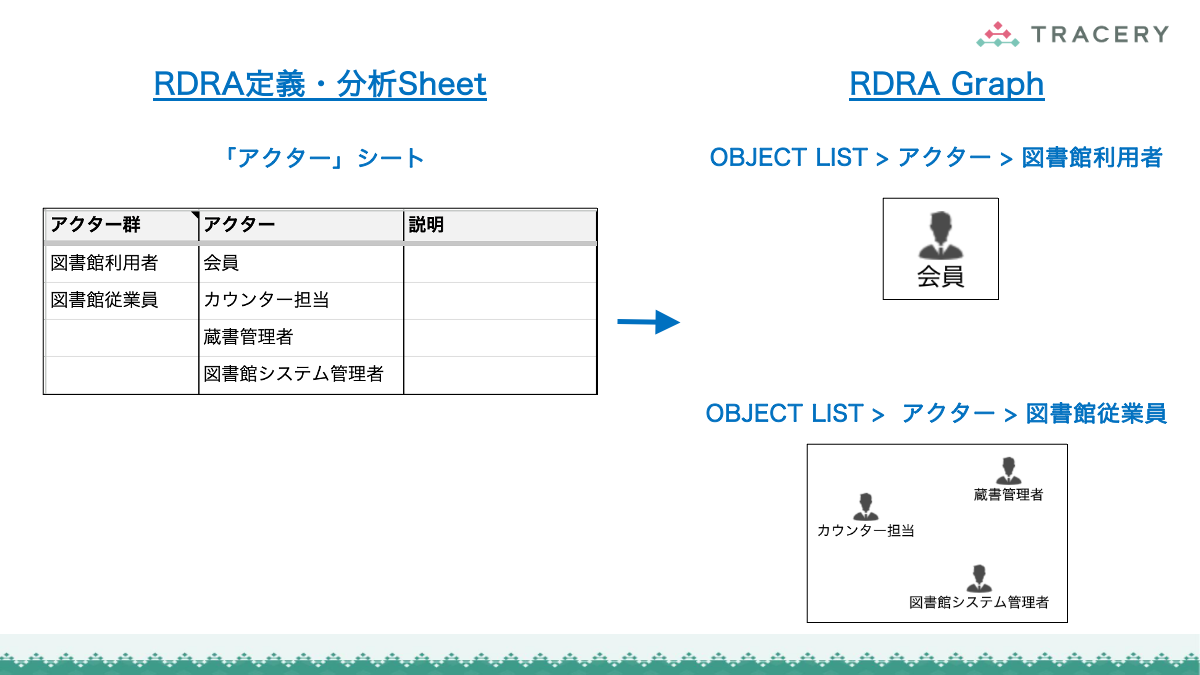
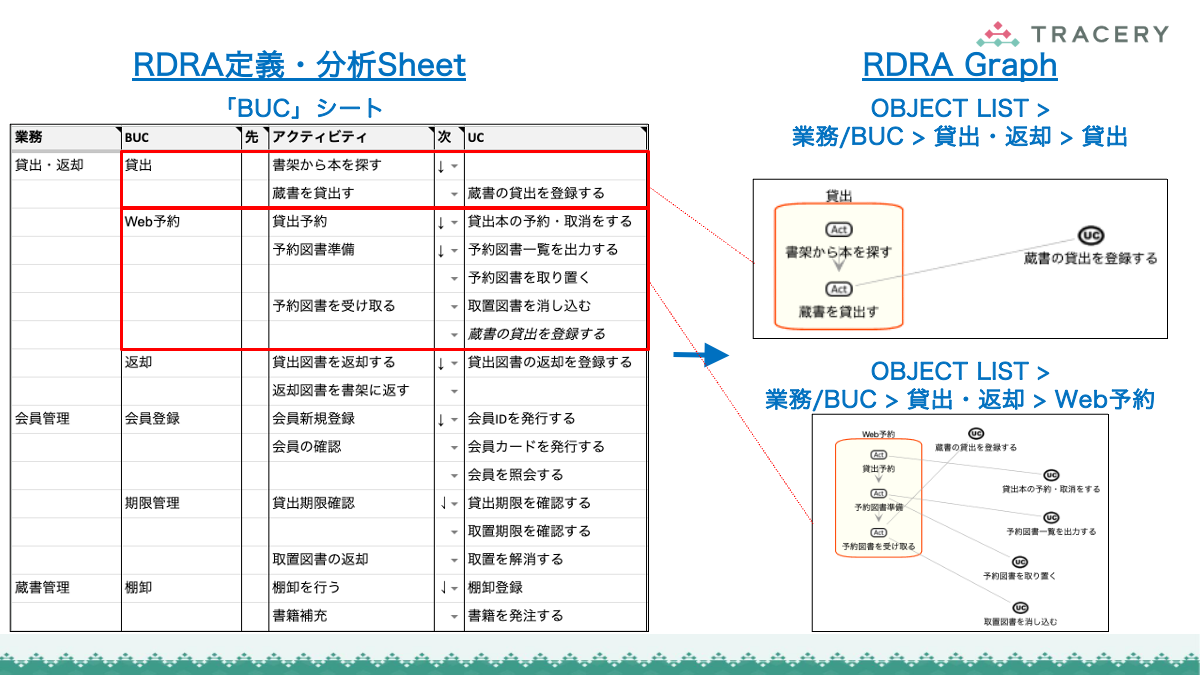
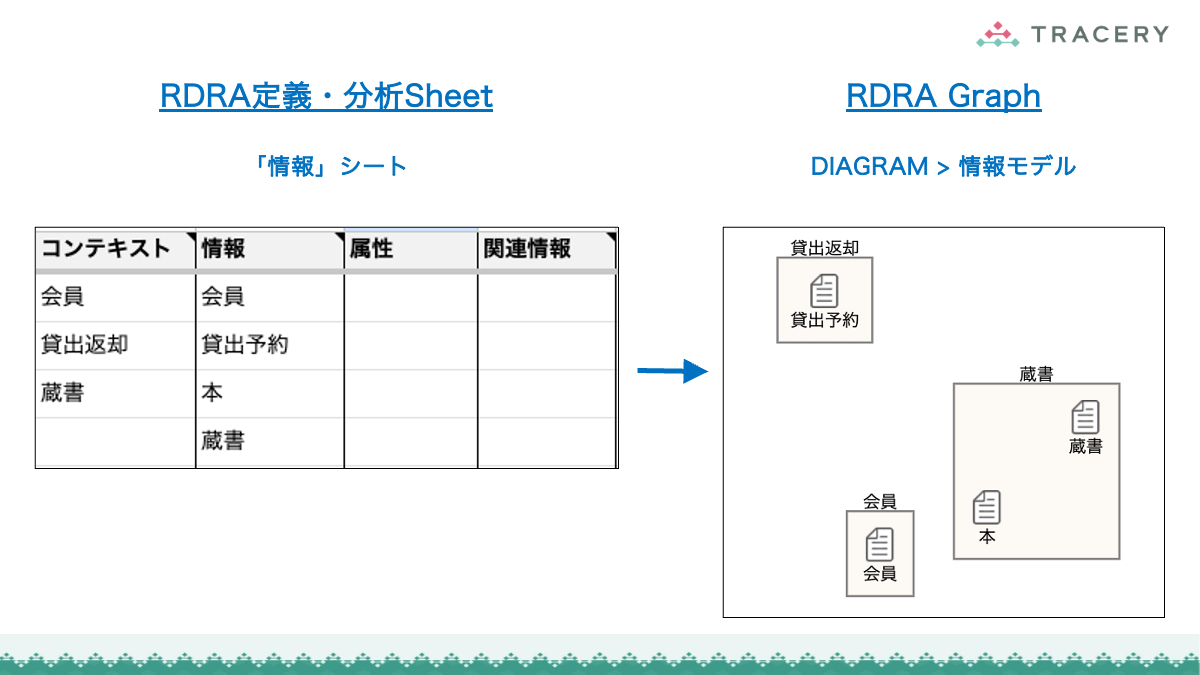
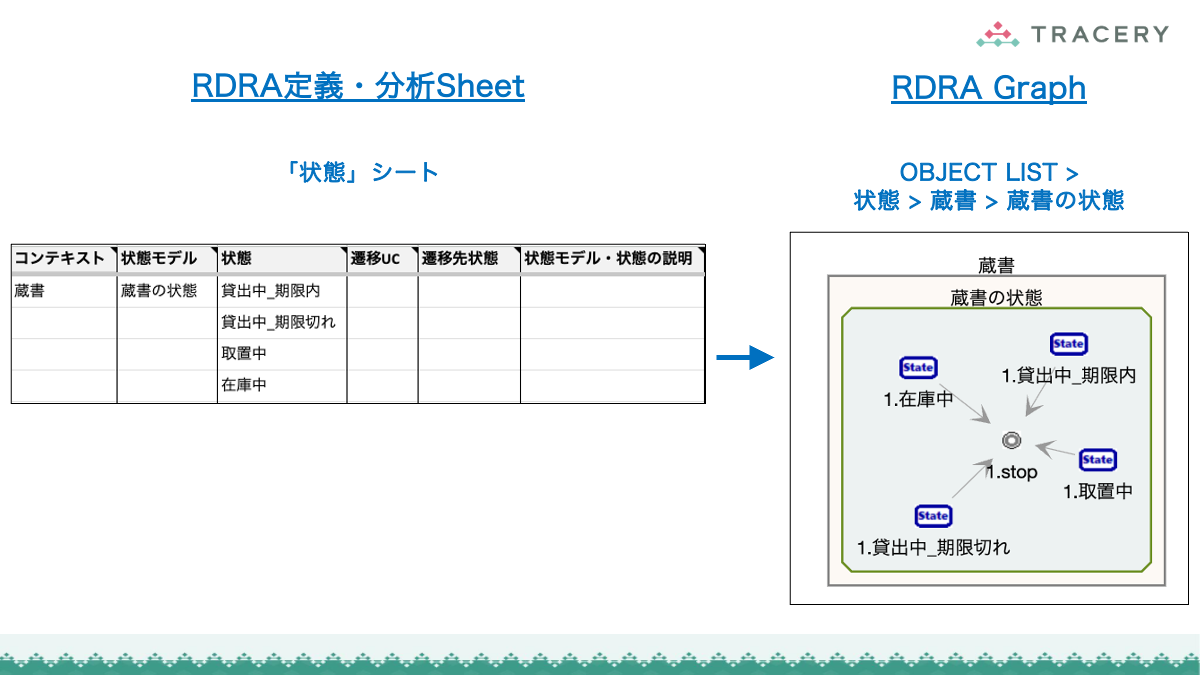
RDRA定義・分析Sheetへのデータ連携
RDRAAgentで生成したデータは、専用のGoogleスプレッドシート(RDRA定義・分析Sheet)に取り込むことで、RDRAの各要素をシート上で一元的に確認・編集できるようになります。以下の手順に従って連携を行ってください。
RDRA定義・分析Sheetをテンプレートからコピーする
以下の手順で「RDRA定義・分析Sheet」を用意してください。
- RDRAAgentのメニューで
12. Spreadsheetに展開:RDRA定義をクリップボードにコピーを選択する - テンプレートのGoogleスプレッドシート(読み取り専用)がブラウザで自動的に開く
- 自分のGoogleドライブにスプレッドシートをコピーする(ヘッダーメニューから
ファイル>コピーを作成)

クリップボード上のテキストを元に「RDRA定義・分析Sheet」上に要件のデータを生成する
コピーして作成したシートに対して以下の操作を実施します。
ZeroOneシートを選択する。- A1セルにクリップボードのテキストを貼り付ける。
- メニューで
12. Spreadsheetに展開:RDRA定義をクリップボードにコピーを選択した時点で、クリップボードにテキストがコピーされている。
- メニューで
ZeroOneシートのImportボタンを押下する。

Importボタン押下後は、いくつかのダイアログが表示されます。下図の手順に従って操作してください(図はmacOS Tahoe 26.2、Chromeの場合)。

取り込みが完了したら、「BUC」シートなど他のシートを開き、データが生成されていることを確認してください。

「RDRA定義・分析Sheet」の使い方・編集方法については、以下の記事を参照してください。
RDRAAgentの活用がもたらす価値
RDRAAgentを活用することで、次のような価値が生まれます。
- 初期立ち上げの圧倒的な高速化
- これまで一から手作業で要件を拾い集め、整理・入力していた負担が劇的に削減されます。白紙から考え始めるという、最もエネルギーを要するフェーズをAIがショートカットしてくれます。
- 本質的な作業への注力
- 入力や作図といった作業時間が減ることで、関係者間での「要件の妥当性検討」「要素間の矛盾の分析」「合意形成」といった、人が本来時間をかけるべき本質的な価値創造の作業に注力できるようになります。
- RDRAという「型」があるからこそ活きるAI活用
- RDRAAgentが高精度な推論を行えるのは、RDRAという確固たる構造的フレームワークが存在するからです。出力すべき要素と関係性が明確に定義されているため、LLMは曖昧な推測ではなく、構造に沿った推論を行うことができます。
AIを活用した要件定義で人が担うべき責任
AIの支援は強力ですが、LLMが生成したモデルはあくまで「叩き台」です。AIの出力をそのまま鵜呑みにしてはいけません。
AIの出力を適切に判断するためには、人がRDRAのモデル構造そのものを正しく理解し、「要件とは何か」という本質を把握していることが不可欠です。
AIが提示した要件の整合性や妥当性を検証し、開発の目的や意図と照らし合わせて最終的な意思決定を行うのは、あくまで人間の責任です。
AIとの共創により、要件定義のプロセスは「人が一から定義する作業」から「AIが生成した要件を人が読み解き、判断する作業」へと進化しています。
最後に
本記事では、要件定義の初期立ち上げを支援するツール「RDRAAgent」を紹介しました。
RDRAAgentを活用することで、構造的で精度の高い要件定義をスピーディーに実践できるようになるでしょう。
次回は、定義した要件を仕様化するためのRDRAAgentの機能「RDRASpec」を紹介します。