2025年8月12日(火)に、TRACERYによるMCP連携が正式リリースとなりました。 正式リリースに先立ち、2025年7月28日(月)に開催された勉強会『BPStudy#215〜MCP連携で加速するAI駆動開発〜』にて、MCPの解説、MCP連携を活用したAI駆動開発の価値・手法の解説とTRACERYを用いたMCP連携のライブデモが行われました。
本記事では、アーカイブ動画の紹介と後半のライブデモの様子を書き起こし記事として紹介します。
MCP連携で加速するAI駆動開発
- その1: TRACERYがMCP対応した理由とその背景
- その2: 設計書からAPIまで──TRACERY連携の実演: 本記事
- イベント概要
- MCPサーバーとTRACERYの紹介・連携デモ
- 質疑応答とデモの総括
イベント概要
登壇者
- スピーカー:
- 清水川 貴之(IT Architect / TRACERY 開発チーム)
- 進行:
- haru(TRACERYプロダクトマネージャー / BPStudy主催)
発表資料
アーカイブ動画
MCPサーバーとTRACERYの紹介・連携デモ
TRACERYへのMCPサーバー機能実装とそのアーキテクチャ

アーカイブ動画チャプター
TRACERYへのMCPサーバー機能実装とそのアーキテクチャ - MCP連携で加速するAI駆動開発【BPStudy215】TRACERY - YouTube
MCP連携先として、弊社のサービスであるTRACERYについてご紹介します。TRACERYはシステム開発のためのドキュメントサービスであり、この度、MCPサーバー機能を追加いたしました。
この場での発表が、本機能について外部で初めてお話しする機会となります。アカウントを作成していただければ、皆様も今すぐこの機能をご利用いただけます。
MCPサーバー機能の追加により、MCP連携を通じてAIからもシステム開発の知識を保存するバックエンドとしてTRACERYを利用できるようになりました。これにより、情報はローカルのリポジトリではなく、ドキュメントを蓄積する場所に集約されます。
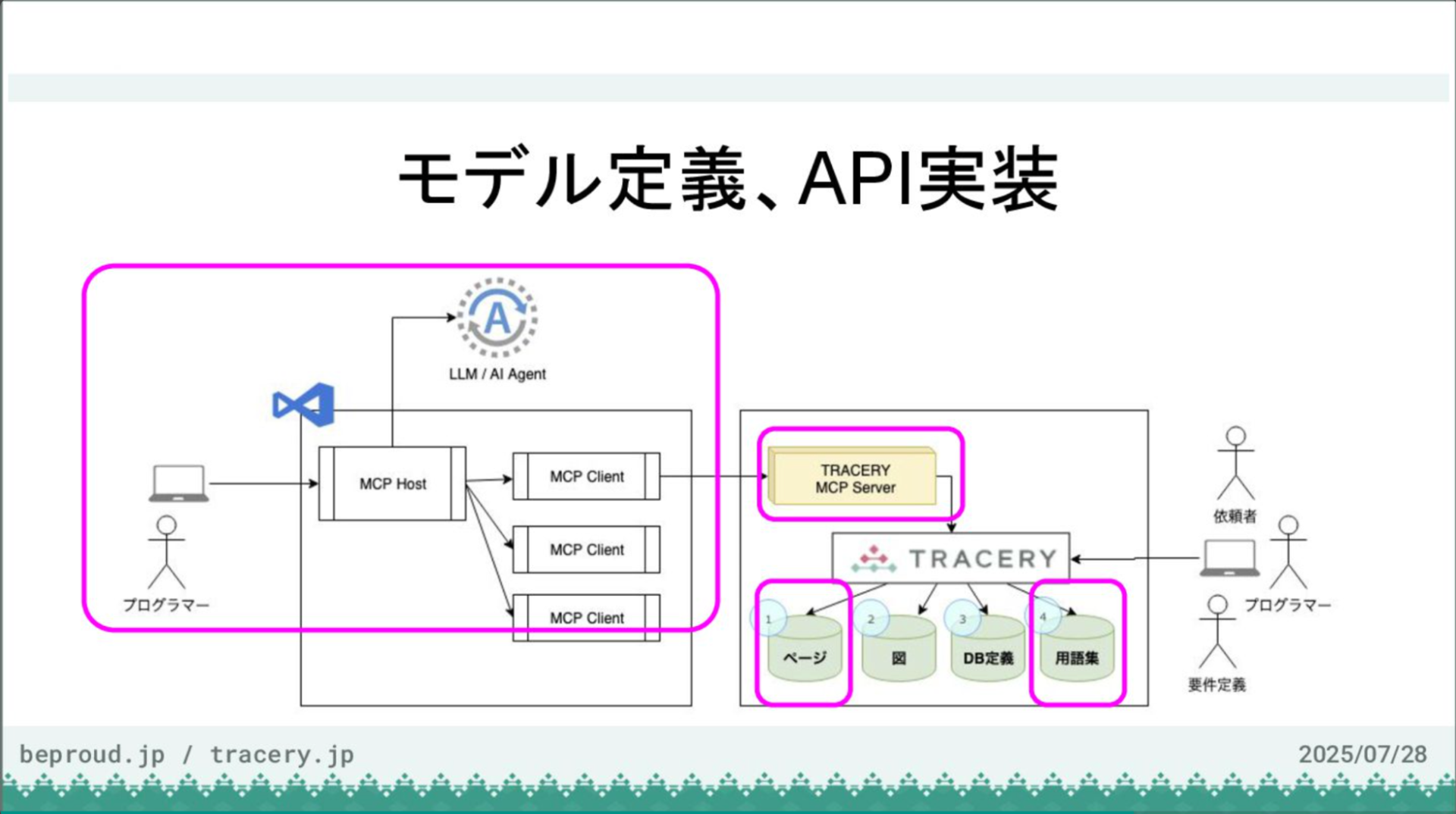
図にあるように、左側のプログラマーはVS CodeやMCP、LLMと連携しながらTRACERYにアクセスできます。
それと同時に、図の右側の依頼者や要件定義者、プログラマーは、従来通りWebインターフェースを通じてWebアプリケーションとしてTRACERYにアクセスし、情報の更新や参照、コメントのやり取りが可能です。このように、双方の使い方が併用できるようになりました。
本日のデモでは、TRACERYとMCPのアーキテクチャの関係を以下の流れで紹介します。
まず、TRACERYに基本的なストック情報を一部用意しておきます。AIはそれを参照しながらコードを記述するなどの活動を行います。そして最後に、AIエージェントが開発結果として得られたストック情報をまとめ、MCPサーバー経由でTRACERYにドキュメントとして保存・更新します。
この一連の流れを通じて、TRACERYの機能をご紹介したいと思います。
デモの前提:ユースケースと技術スタック
アーカイブ動画チャプター
デモの前提:ユースケースと技術スタック・デモの流れ - MCP連携で加速するAI駆動開発【BPStudy215】TRACERY - YouTube
今回のデモの前提となるユースケースは、図書館の貸し出しシステムの開発です。あなたは、この開発チームに新たに参加したメンバーという立場です。チームの現状は、ドキュメントがなく、コードと稼働中のサーバー、ソースコード、データベースのみが存在します。あなたのタスクは、まずシステム全体を把握し、その後、新たな機能を追加することです。
今回のデモで使用するシステムの技術スタックは以下のとおりです。
開発ツールはVisual Studio Code、エージェントはGitHub Copilotエージェント、LLMはClaude Sonnet 4、MCPはTRACERYサーバーを使用します。Webアプリケーションの構成はPython、Django REST framework、MySQLですが、これらのツール、言語、フレームワークの組み合わせに限定されるものではなく、他の構成でも同様に機能します。
開発側でMCPを使えるツールはまだ数が限られていますが、開発対象はWebアプリケーションであるか否か、またPython以外の言語であるか否かに関わらず、動作します。

デモは以下の流れで進めます。まずシステム全体の把握から始め、データベースの構造を理解し、論理名を設定します。次にシステム全体の用語を登録し、追加開発の要件を作成します。
その後、モデル定義やAPI実装といった具体的な開発作業を行い、最後に得られたストック情報を整理してドキュメントに反映させます。この一連の作業を、もし人力のライブデモでコーディングしていたら、20分や30分では到底終わりませんが、AIを活用するとどうなるか、実際に見ていきましょう。

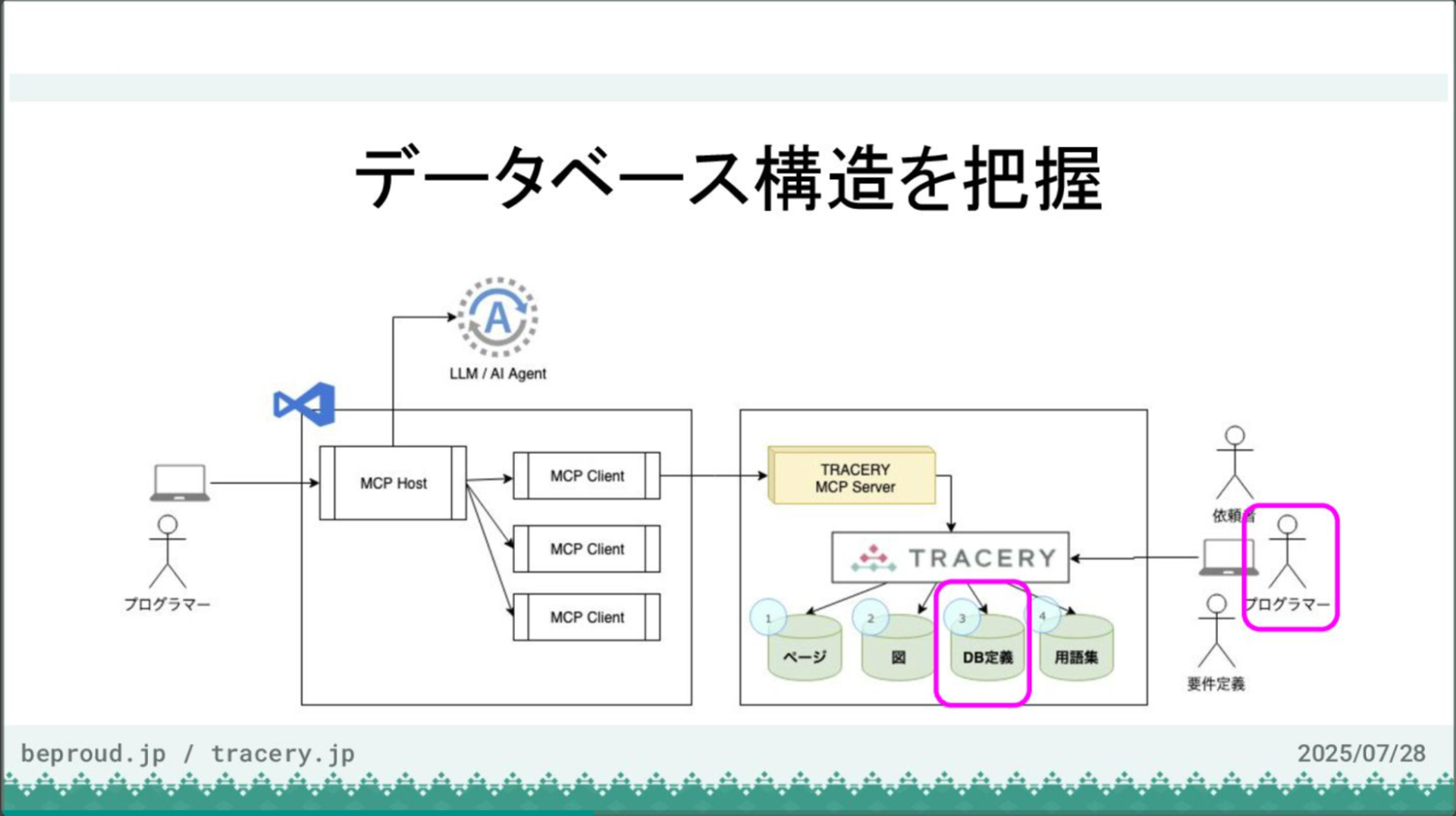
【ステップ1】データベース構造を把握:DB定義のインポート
アーカイブ動画チャプター
データベース構造を把握:DB定義のインポート - MCP連携で加速するAI駆動開発【BPStudy215】TRACERY - YouTube
最初に、データベースの構造を把握します。この作業では、プログラマーがTRACERYを使い、データベース定義を登録していきます。まず、空のTRACERYプロジェクトを用意し、そこにデータベース定義をインポートします。今回は「ABC図書館予約システム」というプロジェクトを使用します。現状はカテゴリーも図もデータベースも空の状態です。
ここにデータベース定義を登録します。MySQLのコマンドで出力したSQLを読み込ませますが、今回は事前に用意したファイルを使ってインポートします。データベース名は「abclibrary」とし、MySQLを選択してファイルをアップロードします。
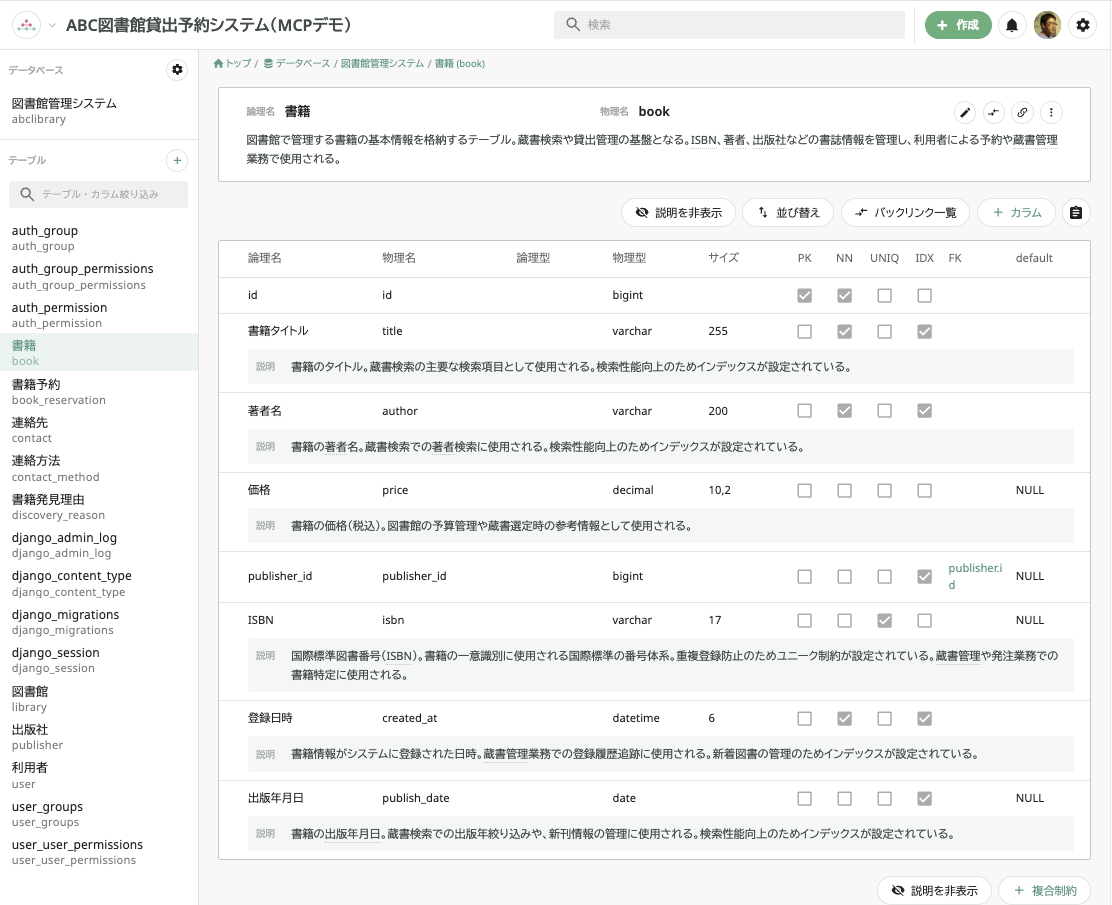
インポートが完了すると、Djangoの管理用テーブルを含め、全てのテーブル定義が取り込まれます。しかし、現状ではどこに何があるのか分かりにくく、論理名も物理名と同じものが設定されているため、例えば「library」テーブルを見てもIDとNameだけではその役割を完全に理解するのは難しい状態です。そのため、まずは現状のデータベース論理名をTRACERYに取り込み、可視化するところから始めましょう。
【ステップ2】AIによるドキュメント拡充:DB論理名と説明の自動付与
アーカイブ動画チャプター
AIによるドキュメント拡充:DB論理名と説明の自動付与 - MCP連携で加速するAI駆動開発【BPStudy215】TRACERY - YouTube
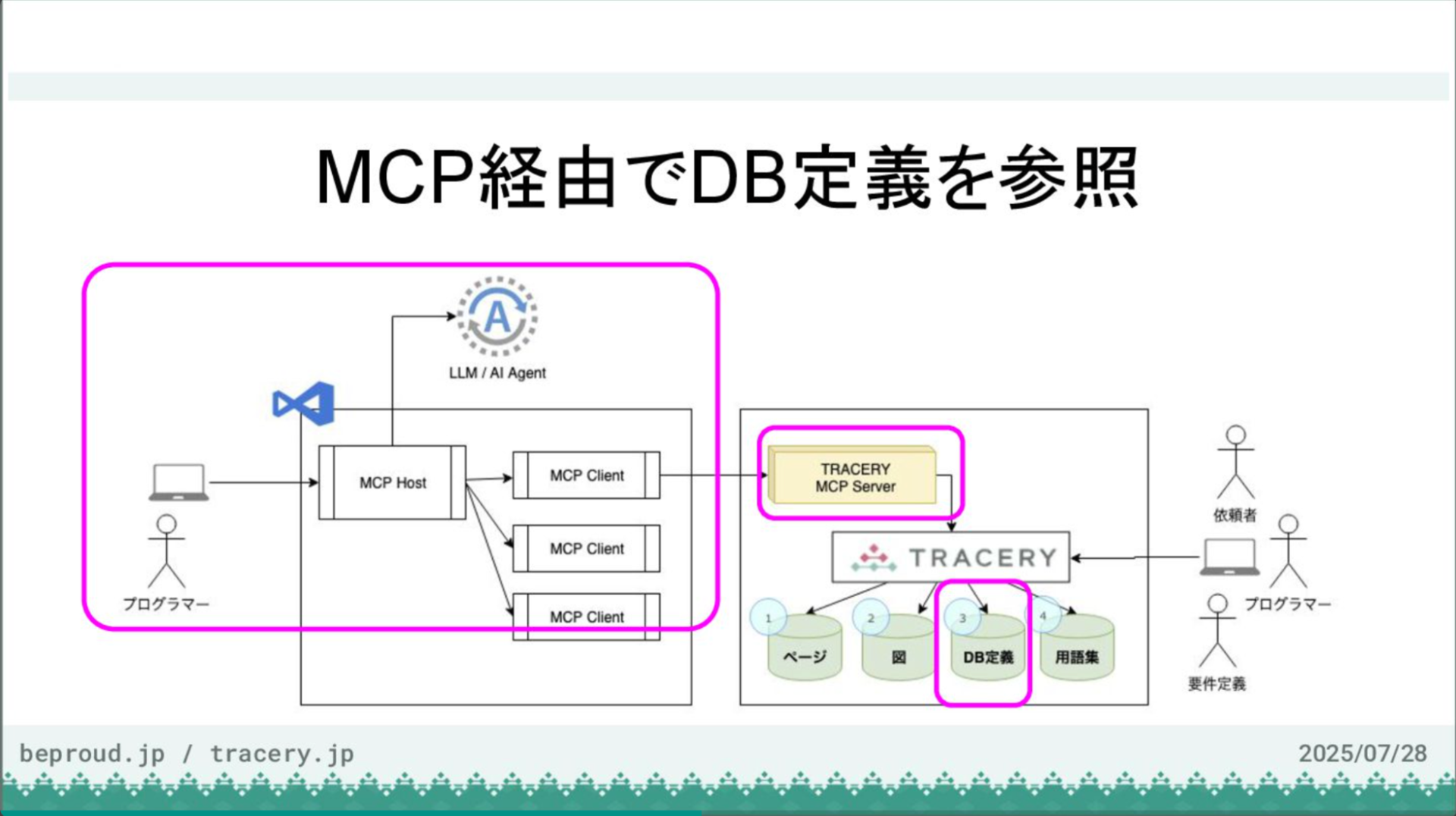
MCP経由でデータベース定義を参照します。ここでMCPの登場です。
まず、VS CodeとMCPサーバーを接続し、データベース定義が参照できるかを確認します。Copilotとの対話を開始し、MCPサーバーを追加します。今回はHTTPで接続するため、トランスポートにHTTPを選択し、TRACERYのURLに「/mcp/」を追加したものを入力します。
サーバー名は「tracery-lib」とし、リモート設定に保存します。外部サイトでの認証を許可し、ログイン後にプロジェクトを選択して認可を行うと、VS Codeに戻ります。これで33個のツールが利用可能になりました。
確認すると、ローカルMCPに加えて、TRACERYのMCPサーバーが提供するツール群が認識されていることがわかります。
接続が確認できたので、Copilotに「tracery-libで使えるツールを確認してください」と指示します。
すると、Copilotは利用可能なツールを認識し、一覧を表示してくれました。削除系の操作は破壊的であるという注意書きも添えられているのが分かります。問題なく連携できているようです。
プロンプト
#tracery-lib で使えるMCPツールを確認してください
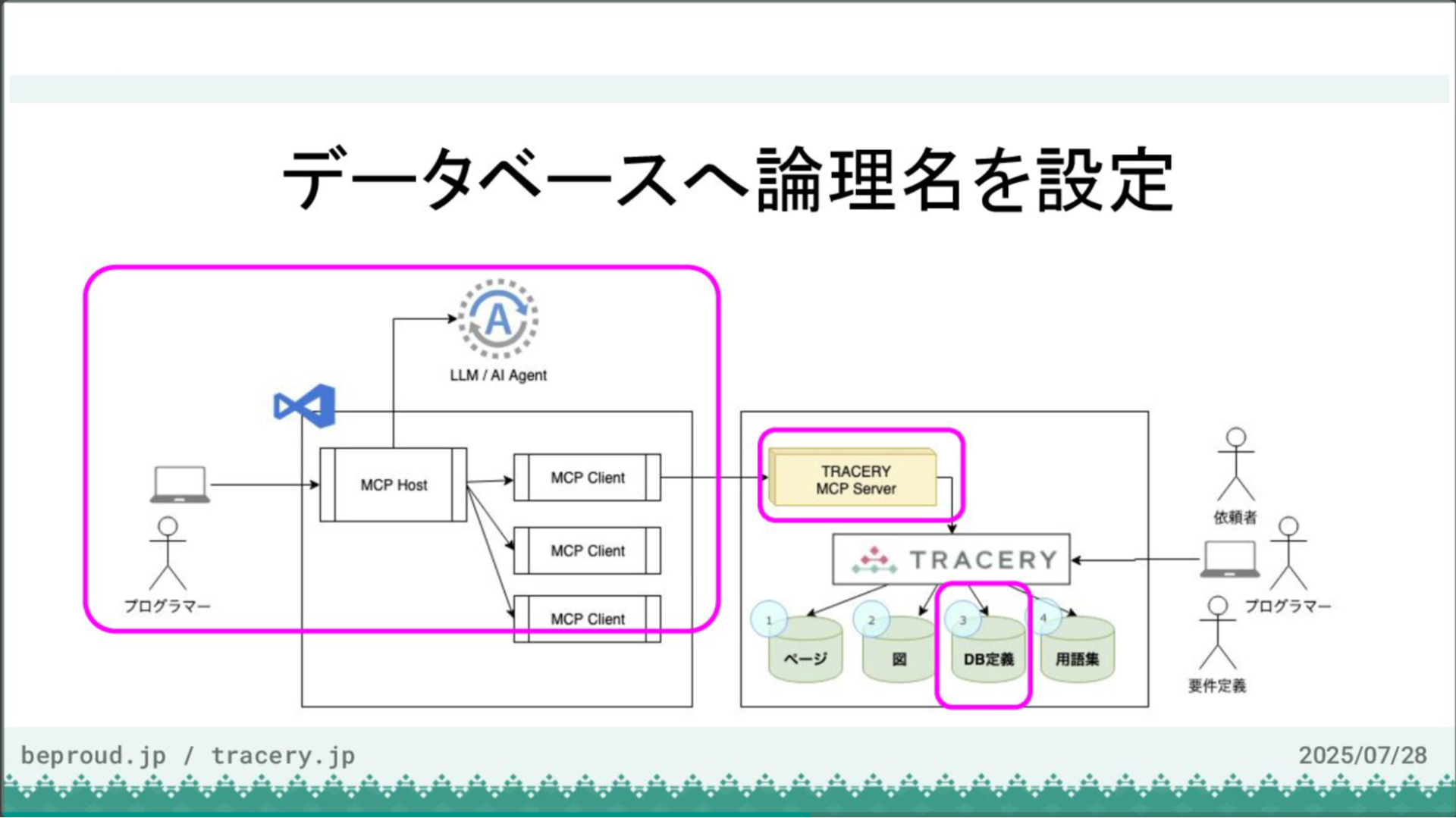
VS CodeとTRACERYの接続が完了しましたので、次にデータベースに論理名を設定していきます。
現状では論理名が設定されておらず、内容の把握が困難なため、これを改善します。今回はモデルの用途もAIに推測させて設定してもらいます。
プロンプトは、「models.pyを基にDB定義の論理名を設定してください。また、TRACERYのコメント欄に、その論理名の根拠となる用途などの追加情報を記載してください」といった内容です。
プロンプト- models.py を元に、DB定義の論理名を設定してください。
- また、DB定義にコメント(説明、概要)を設定してください。
- 概要には、論理名を元にどのような用途なのか追加情報を記載してください。
- 概要はidやFKなど明確なものには不要ですが、説明が必要であれば設定してください。
- INDEXやUNIQUE等の制約を付けた理由を伝える必要があれば、概要に追記してください。
この指示に基づき、AIはまず既存のデータベース定義を全て取得し、その内容を分析します。そして、それぞれのテーブルやカラムに適切と思われる論理名と説明を付与し、TRACERYの情報を更新していきます。
この一連の作業は、更新系のAPIを呼び出すため、実行前にユーザーの許可を求めるプロンプトが表示されます。セッション中の許可を選択すると、以降の同様の操作は自動で実行されます。
この許可の仕組みは、CopilotにIssueをアサインして全自動でPull Request作成まで行うシナリオでは、許可するツールを事前に設定しておきます。これによって、AIは確認なしで安全な範囲の操作を自動実行できます。
作業が完了し、TRACERYの画面を更新すると、各テーブルやカラムに論理名や説明が追加されていることが確認できます。
例えば、「書籍予約」や「出版社」といった、より分かりやすい名称が設定されました。このように、AIを活用することで、データベースのドキュメント化を効率的に進めることができます。
【ステップ3】開発の共通言語づくり:用語集の自動登録
アーカイブ動画チャプター
開発の共通言語づくり:用語集の自動登録 - MCP連携で加速するAI駆動開発【BPStudy215】TRACERY - YouTube
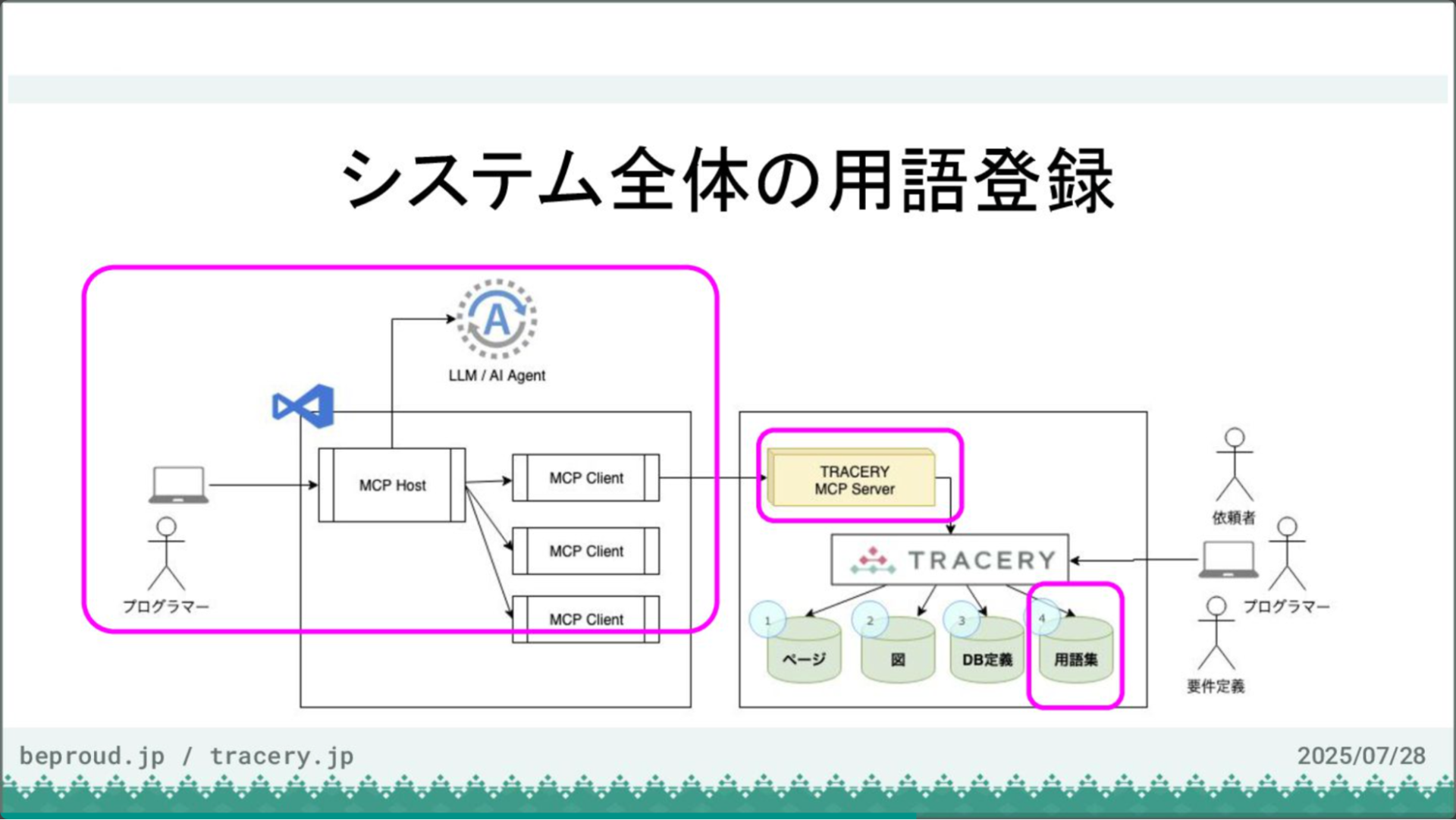
次に、システム全体の用語登録を行います。システム開発においては、関係者間で共通の用語を使用することが重要です。また、その用語に対応したコーディング規約上の名称を定義し、実装に反映させる必要もあります。
LLMがソースコードを扱う際、用語を誤解して独自の解釈で実装を進めてしまうことがありますが、あらかじめ用語集を定義しておくことで、こうした問題を未然に防ぐことができます。
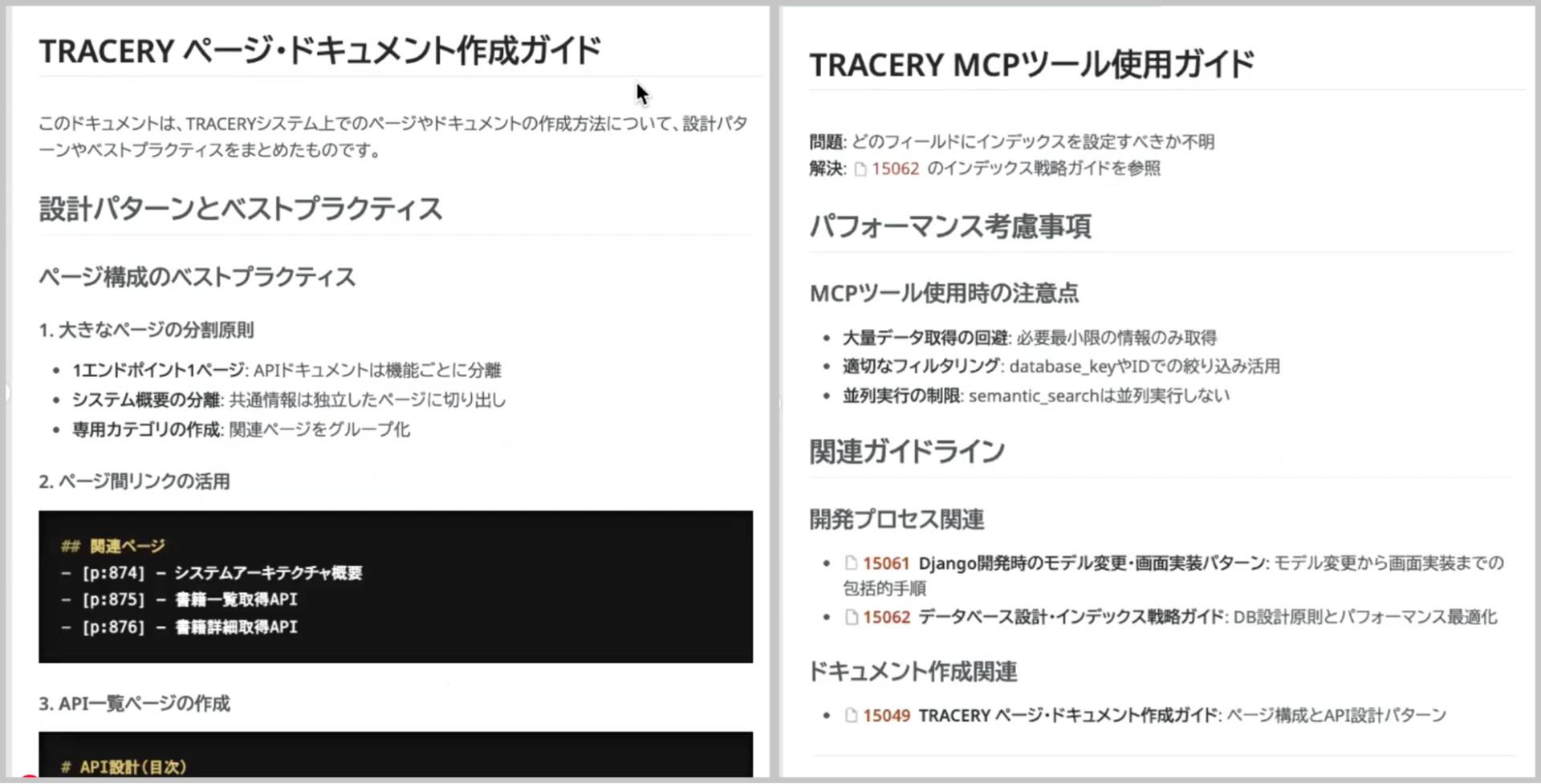
そこでまず、AIに作業の前提となるドキュメントを渡します。今回は「ページ・ドキュメント作成ガイド」と「TRACERY MCPツール使用ガイド」という2つのファイルをTRACERYに登録しました。
これらには、TRACERYの基本的な使い方やドキュメント作成の作法などが記述されており、AIがこれらを理解することで、より適切なアウトプットが期待できます。
準備が整ったところで、AIに用語登録を依頼します。プロンプトは「DB定義とソースコードを基に用語を登録してください。用語はカテゴリー分けし、関連するものをグループ化してください。開発ガイドラインも参照してください」といった内容です。
この指示を受け、AIはまず「システム・技術」「図書館業務」「書籍・出版」といったカテゴリーを自動で作成し、その後、各カテゴリーに対応する用語を次々と登録していきます。「書籍予約」や「貸出業務」といった用語が、コーディング用の名称や詳細な説明とともに登録されているのが確認できます。
このように、AIに用語集の作成を任せることで、開発の初期段階で必要なドキュメント整備を迅速に行うことが可能です。
プロンプト- DB定義とソースコードに基づいて、用語を登録してください。
- 用語はカテゴリごとに分類し、関連する用語をグループ化してください。
- 用語のうち、優先度が高いのは、対象ドメインの専門用語です。
- 他にも、システム用語や業務用語など、関連する用語を登録してください。
- 開発関連の用語は知名度の低いものだけでOK. 例えばDjangoやPythonなどの有名なものは登録しなくてOKです。
- コーディング用名称は小文字のスネークケース

【ステップ4】追加開発の開始:要件準備とAPI設計・自動実装
アーカイブ動画チャプター
追加開発の開始:要件準備とAPI設計・自動実装 - MCP連携で加速するAI駆動開発【BPStudy215】TRACERY - YouTube
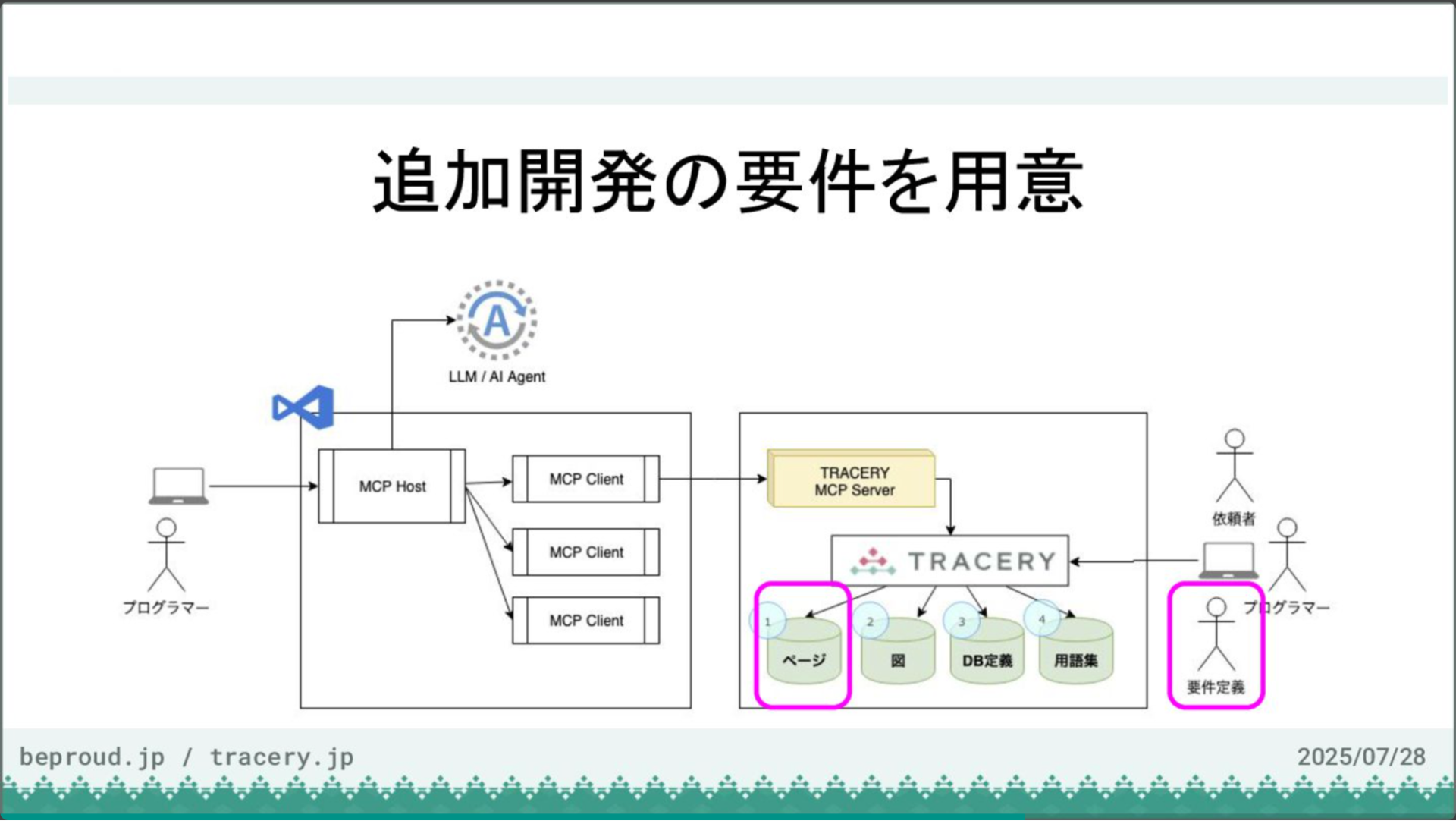
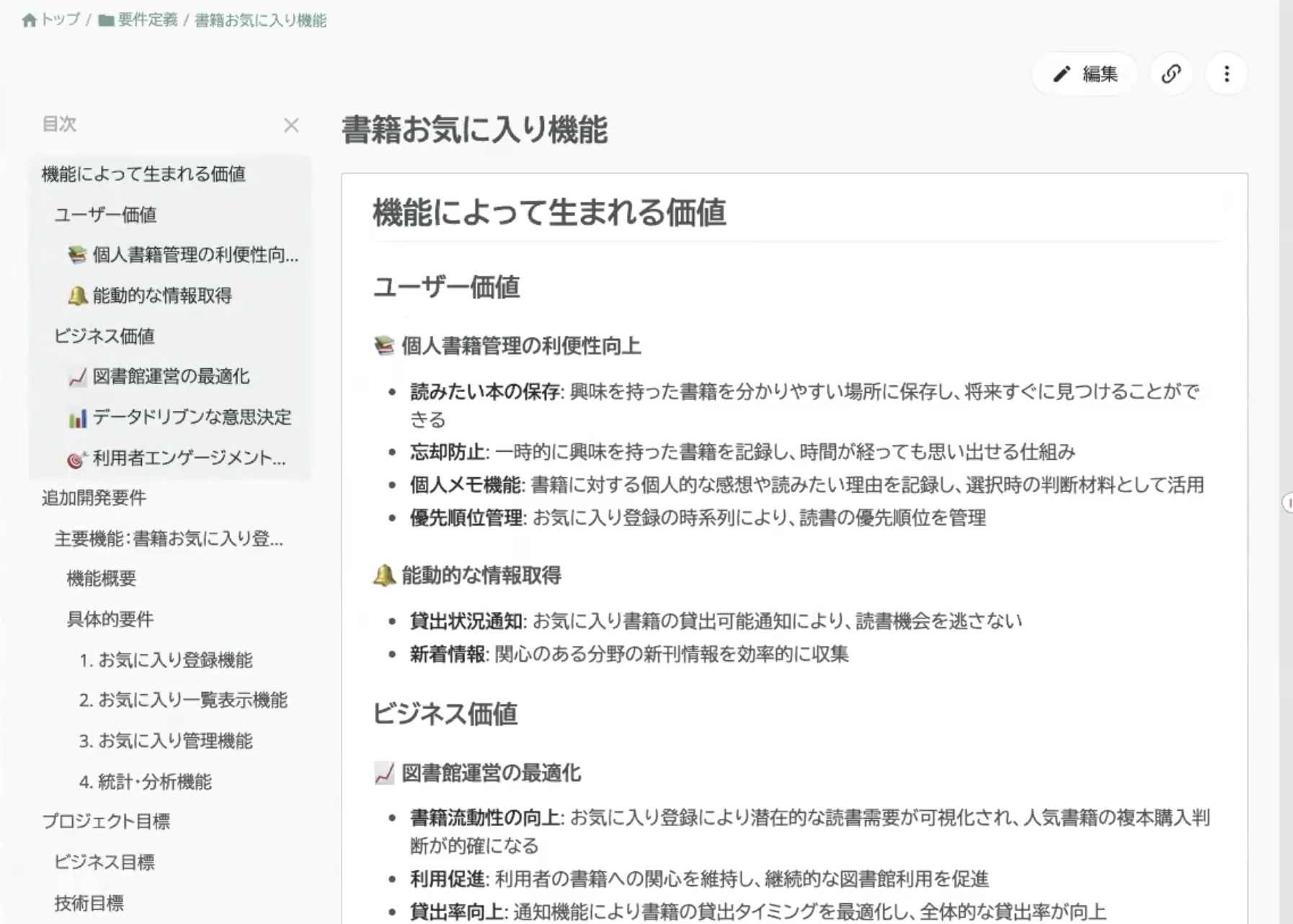
次に追加開発の要件を用意します。GitHub Issueに「書籍お気に入り機能」の追加要件をあらかじめ用意しておきました。
ユーザー価値やビジネス価値にも触れられており、詳細な機能仕様が定義されています。このシステムは、フロントエンドとはREST APIで連携しているという想定です。では、このGitHub Issueの要件をTRACERYにコピーし、ストック情報としてTRACERY上で一元管理できるようにします。
要件が登録できたので、次はいよいよモデル定義とAPI実装に移ります。
まず、先ほど登録した要件を基に、フロントエンド向けの新機能に必要なAPI設計をAIに依頼します。
その際、設計内容は一度人間がレビューできるよう、ローカルのマークダウンファイルに出力してもらうように指示します。
AIは指示を受けると、まずTRACERYから要件を読み込み、既存のソースコードを調査して、お気に入り機能に関連するモデルが存在するかなどを確認します。
プロンプト- TRACERYで、要件「書籍お気に入り機能」を確認して、要件を満たすのに必要なAPIを教えてください。

分析の結果、AIはお気に入り機能を実現するために必要なAPIのエンドポイント一覧を提案してくれました。
今回は時間の都合上、統計分析APIは不要であると伝え、それ以外の必要最低限のテーブル設計とAPI設計を再度まとめてもらい、デザイン用のマークダウンファイルとして出力させます。
プロンプト今回は時間の都合で、統計分析APIは不要です。
それ以外の必要最低限のモデル定義とAPIをまとめてください。
- まずはテーブル設計を行って、design.md ファイルに書いてください。
- それを元にAPI設計を design.md ファイルに書いてください。

ファイルが出力されたので、その内容を確認します。6つのエンドポイントが提案されています。
本来であれば、ここで人間が設計内容を精査し、必要に応じて修正しますが、今回はこの内容で実装を進めるようAIに指示します。
プロンプト- この内容で実装してください。
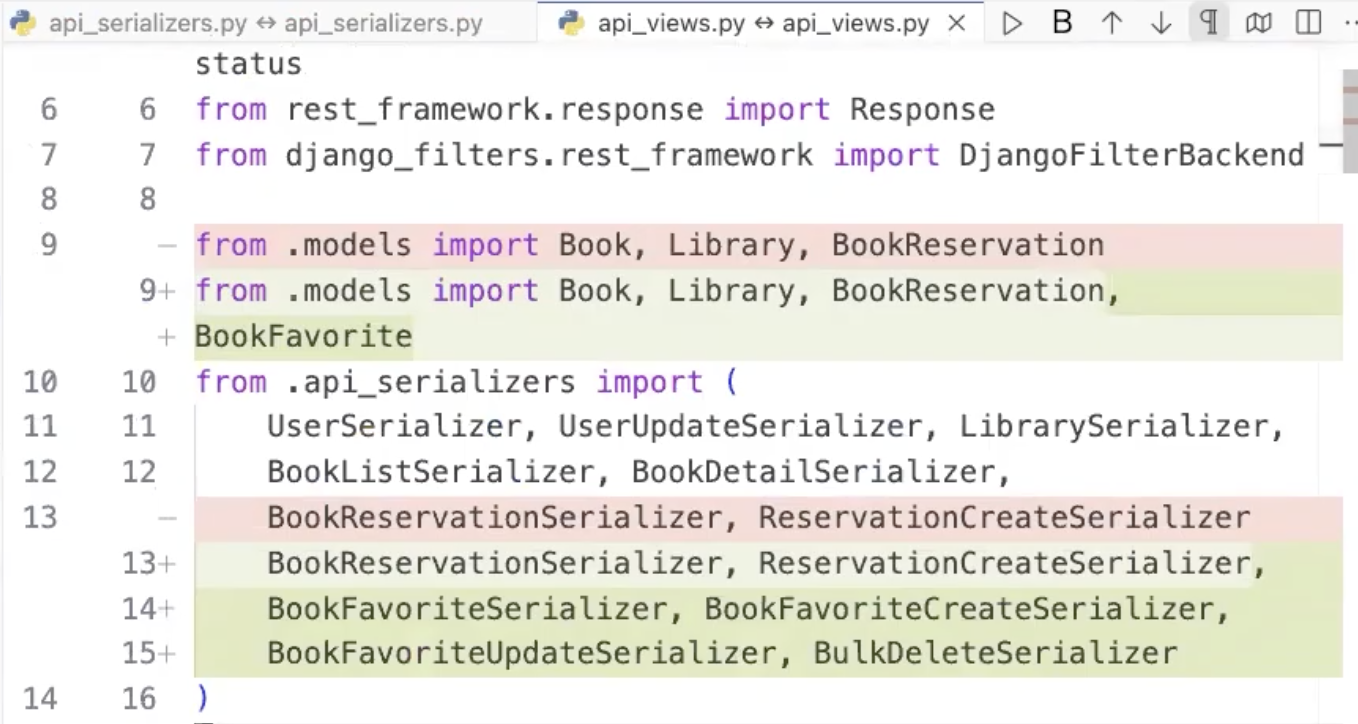
AIは指示に基づき、モデル定義を追加し、マイグレーションファイルを作成・実行します。これにより、データベースに新しいテーブルが作成されます。
次に、JSONとモデルのマッピングを行うシリアライザー、ビジネスロジックを記述するビュー、そしてURLのルーティング設定を順次実装していきます。
さらに、管理画面からもこの新機能が操作できるように、Django Adminの設定も自動で追加してくれました。

【ステップ5】成果のストック化:開発結果のドキュメント登録
アーカイブ動画チャプター
成果のストック化:開発結果のドキュメント登録 - MCP連携で加速するAI駆動開発【BPStudy215】TRACERY - YouTube
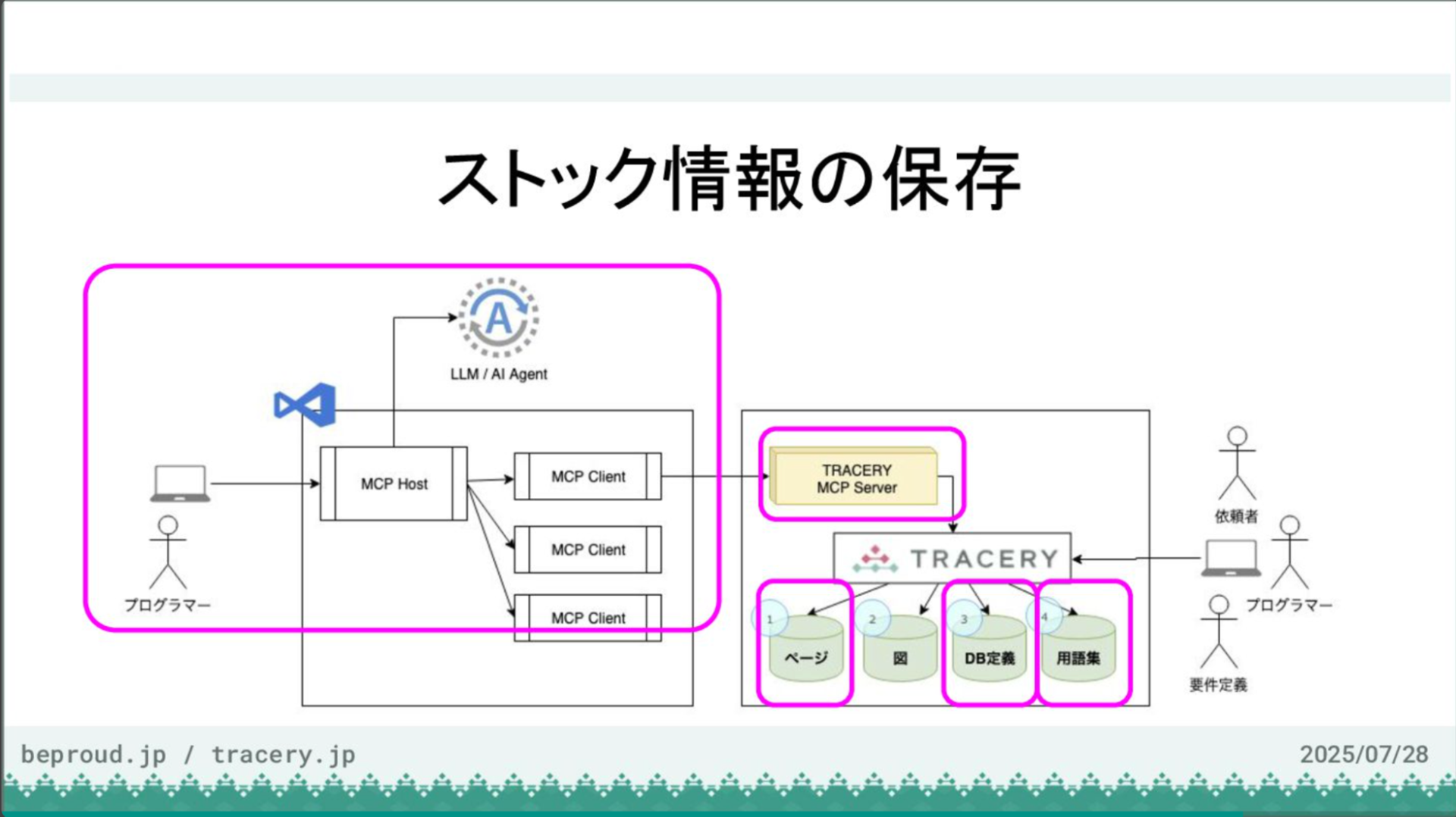
最後に、この開発で得られた成果をストック情報として整理し、ドキュメントに反映させます。
これまでは設計や実装の過程で、様々な情報がフロー情報としてやり取りされていましたが、最終的な成果物(DB設計、API設計、新しい用語など)を、あらかじめ用意しておいたドキュメント作成ガイドに従ってTRACERYに登録するようAIに指示します。
プロンプト- 実装した結果を「DB設計」「API設計」「新しい用語」にまとめ、TRACERYに登録してください。
- まとめ方は、開発ガイドラインの「TRACERY ページ・ドキュメント作成ガイド」を参照してください。
指示を受けたAIは、まず「DB設計」や「API設計」といった新しいカテゴリーを作成し、その後、それぞれのページに内容を記述していきます。これで、開発の成果がドキュメントとして正式に保存されました。
ストック情報の活用:TRACERYの、トレーサビリティ機能の紹介
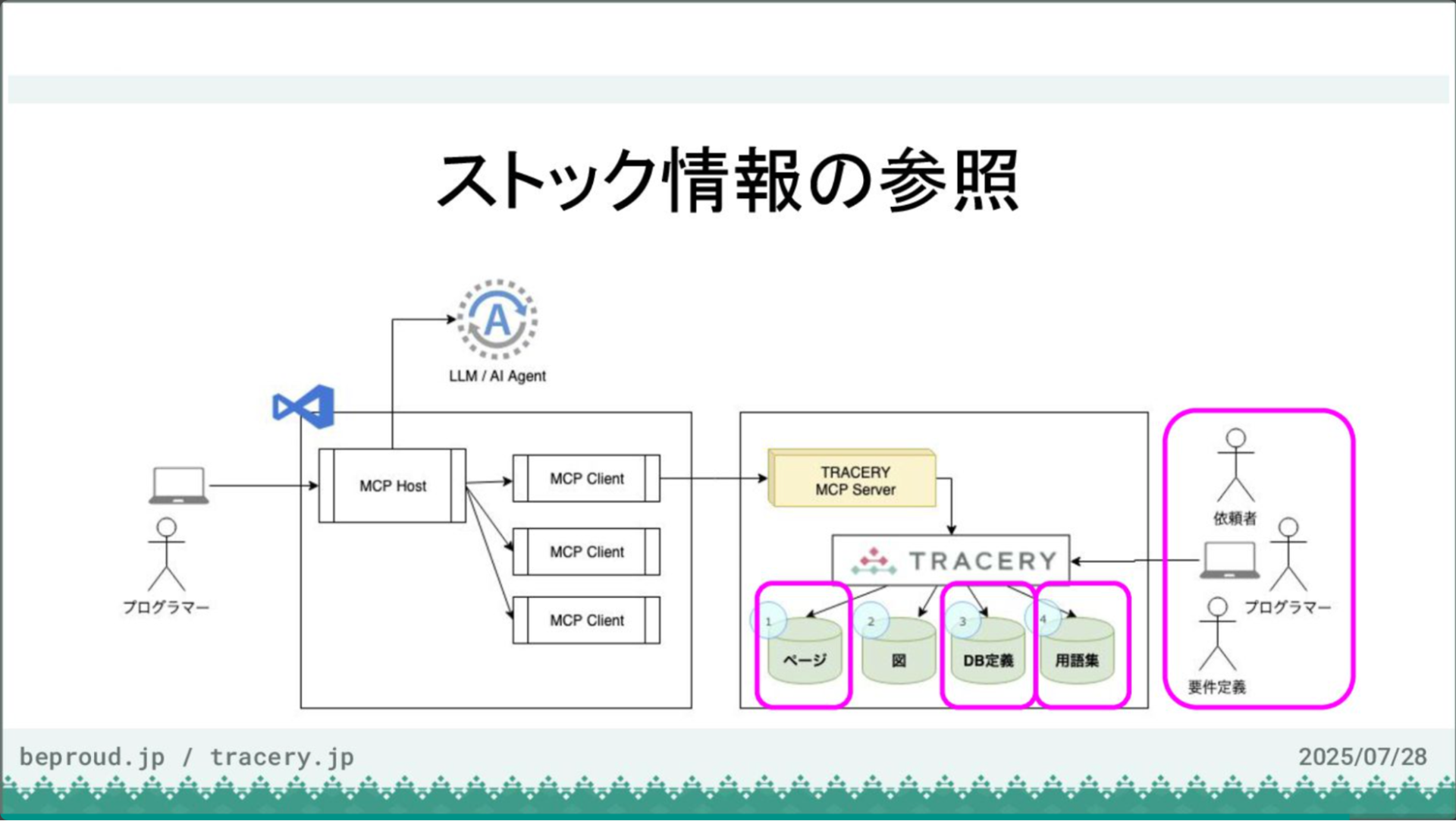
これまでは開発者側の視点で、VS Codeなどを使って作業を進めてきました。ここからは、作成されたストック情報を参照する側の視点で見ていきます。
TRACERYには、作成されたページやDB定義、用語集といった情報が蓄積されています。今回はデモに含めませんでしたが、業務フロー図などを基に設計を起こさせることも可能です。
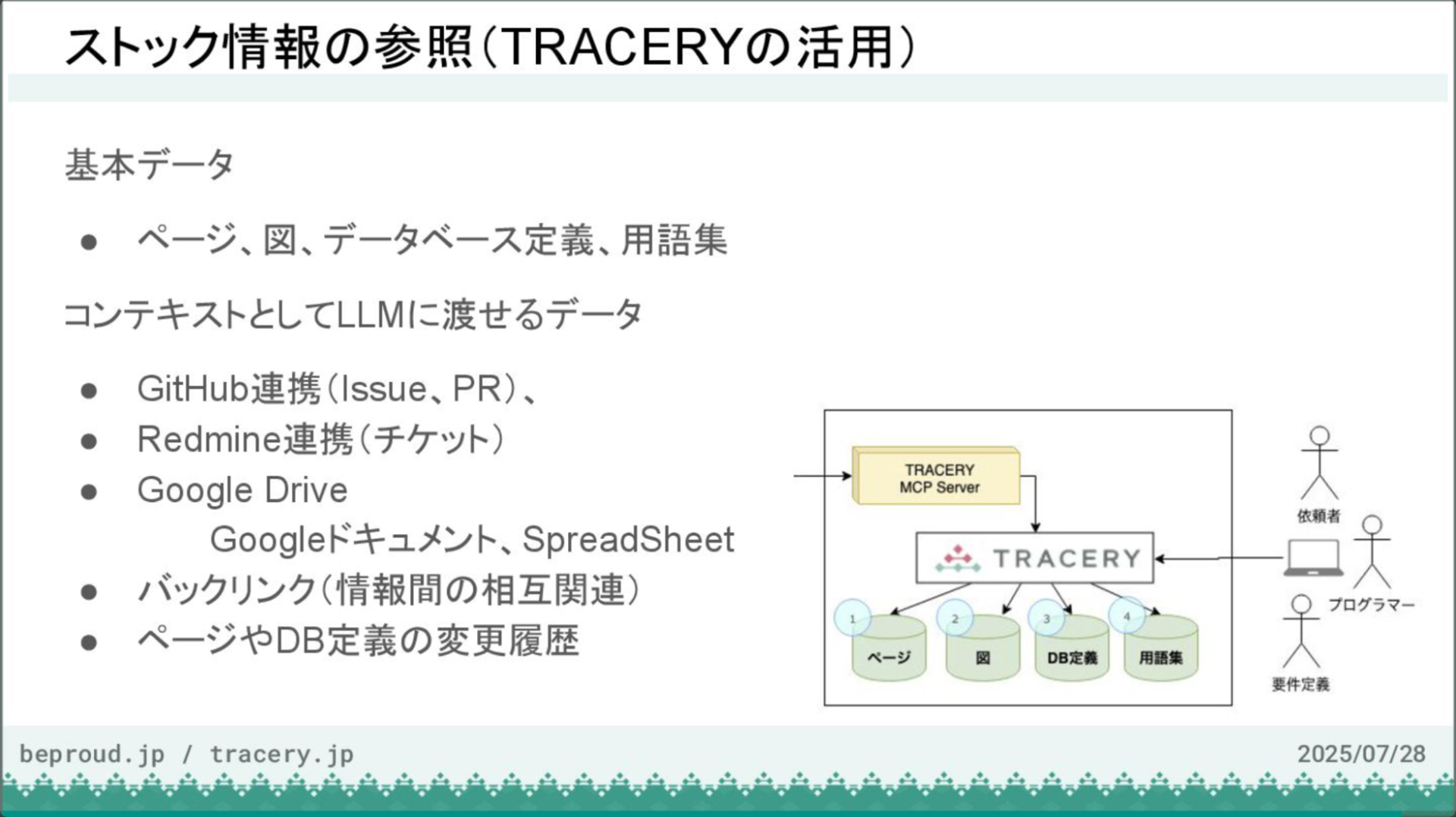
TRACERYの大きな特徴の一つに、トレーサビリティ機能があります。例えば、GitHubと連携設定を行うことで、ドキュメントから関連するIssueやPull Requestを直接参照できます。同様に、Google Driveと連携すれば、関連するドキュメントやスプレッドシートへのリンクも可能です。
また、バックリンク機能は、ある情報がどこから参照されているかを逆引きで表示する機能です。例えば、「書籍予約」という用語がどのドキュメントで使われているか、あるいは「図書館」というデータベースのテーブルがどのAPIから参照されているかなどを一覧で確認できます。
このトレーサビリティは、LLMに渡すコンテキストとしても非常に有効です。
例えば、あるカラムを削除しようとした際に、その影響範囲をAIが正確に把握し、「関連するページの分類情報が失われます」といった警告を発したり、より安全な更新方法を提案したりすることが可能になります。これにより、意図しない破壊的な変更を防ぎ、開発の安全性を高めることができます。
さらに、コメント機能により、ドキュメント上で直接ディスカッションを行い、修正や確認を進めることができます。このように、TRACERYは開発の成果物をストックし、多様な関係者がそれを活用するためのプラットフォームとして機能します。
質疑応答とデモの総括
質疑応答パートのアーカイブ動画
アーカイブ動画チャプター
質疑応答とデモの総括 - MCP連携で加速するAI駆動開発【BPStudy215】TRACERY - YouTube
質疑応答
Q. TRACERYのMCPサーバーは、どのような実装や定義でVS Codeからの呼び出しを実現していますか?
TRACERYは基本的にMCPの公式リポジトリにある python-sdk に準拠して実装されています。重要なのは、AIにツールの使い方を正しく理解させるために、各ツールに詳細な説明(ディスクリプション)を記述している点です。
例えば、単純な足し算の「add」というツールでも、その機能だけでなく、どのような場面で使うべきかといった情報まで含めています。
TRACERYのツールで言えば、search_textというページ検索ツールには「開発ドキュメントからテキスト検索を実行し、検索結果の文字列を返します」といった説明を付けています。
また、削除のような破壊的な操作を伴うツールには、「これは破壊的オペレーションです。事前に必ずユーザーに確認してください」といった警告文を入れることで、AIの行動を抑制するようにしています。
例えば、カテゴリーを削除すると関連ページの分類情報が失われるため、代わりに更新用のAPIを使うことを推奨する、といった具合です。
もちろん、これだけで完全にAIの行動を制御できるわけではありませんが、意図しない操作を防ぐ効果はあります。そして、完全に抑制できない部分については、デモでもあったように、実行前に人間が許可・不許可を判断するプロンプトが表示される仕組みになっています。
LLMはクライアント側が持っているツール一覧情報の中から、命令に対して最も適切なツールを自律的に選んで実行します。直接「このツールを使って」と指示することも可能ですが、基本的にはAIに判断を委ねています。
Q. トレーサビリティ情報は、今後LLMにコンテキストとして渡す予定のものですか?
はい、その通りです。GitHubのIssueやGoogle Drive上のドキュメントもそうですが、特に伝えたかったのはTRACERYならではのトレーサビリティ情報です。
GitHub上でナレッジを管理する方法では難しい、バックリンクなどを使った逆方向のトラッキング情報を渡せるようになる予定です。
例えば「このデータベースカラムはどこから参照されているか」といった情報をコンテキストとして渡せるようになると、AIは変更による影響範囲をより正確に把握できるようになります。
Q. この作業でハルシネーションはどの程度発生しますか?
ある意味、今回のデモでAIが生成した「図書館の業務」に関する内容は、全てAIの創造、つまりハルシネーションの塊と言えるかもしれません。しかし、あらかじめ適切なドキュメントを渡しておくことで、その内容に沿ったアウトプットを生成するように、ある程度は制御が可能です。
そして、最も重要なのは、生成されたものを鵜呑みにしないことです。APIの設計なども、AIの提案をそのまま採用すると、実は構造的に良くなかったということも大いにあり得ます。ですから、最終的には人間が確認するプロセスが必須だと考えています。
Q. チャットで利用する言語は日本語以外も可能ですか? また、MCPサーバー提供者として考慮すべきことはありますか?
チャットウィンドウに入力する言語はどの言語でも大丈夫です。基本的には、ツールのディスクリプションは英語で記述するのが一般的かと思います。今回のデモでは、トレーサリーが日本語話者向けであるため日本語で記述しました。
どのような言語で記述しても、LLMが利用者の言語に合わせて自動的に翻訳・解釈してくれるので、基本的には問題ありません。
したがって、そのツールを誰が使うのかという点に着目し、対象者に最も分かりやすい言語でディスクリプションを記述するのが良いでしょう。
オープンソースやグローバルに展開するサービスであれば、英語で記述するのが無難かと思います。
デモの総括:AI駆動開発の可能性
進行(haru):今日のデモの重要なポイントは、これまで人手で時間と手間をかけて行っていた作業の多くを、AIによって自動化した点です。具体的には、まずデータベースの定義や用語集といった基本的なドキュメントを、LLMに自動で作成させました。ちまちまと手作業で入力するのではなく、一括で生成できるのが大きな利点です。
次に、そのドキュメントと要件定義を基に、実際のコードをAIに生成させました。そして、それが実際に動作するものが出来上がったわけです。これも全て自動で行われました。
そして最後に、開発の成果を、今後の継続的な開発のためにストック情報として再びドキュメントに保存しました。この一連のサイクル、つまり「ドキュメント化→実装→ドキュメント化」を、人間が介在することなく、ほとんどAIの力だけで完結させたのが今回のデモです。
人の手であれば2日や3日かかると見積もるような作業が、途中のやり取りを含めても45分から1時間程度で完了しました。この圧倒的な効率化が、AI駆動開発の大きな可能性を示していると言えるでしょう。
閉会の挨拶
進行(haru):本日の発表は以上となります。登壇いただいた清水川さんに、皆様、今一度大きな拍手をお願いいたします。
ありがとうございました。